整体架构
引擎:Spark。
支持批处理和流模式两种数据质量检测方式。
在Griffin的架构中,主要分为Define、Measure和Analyze三个部分:
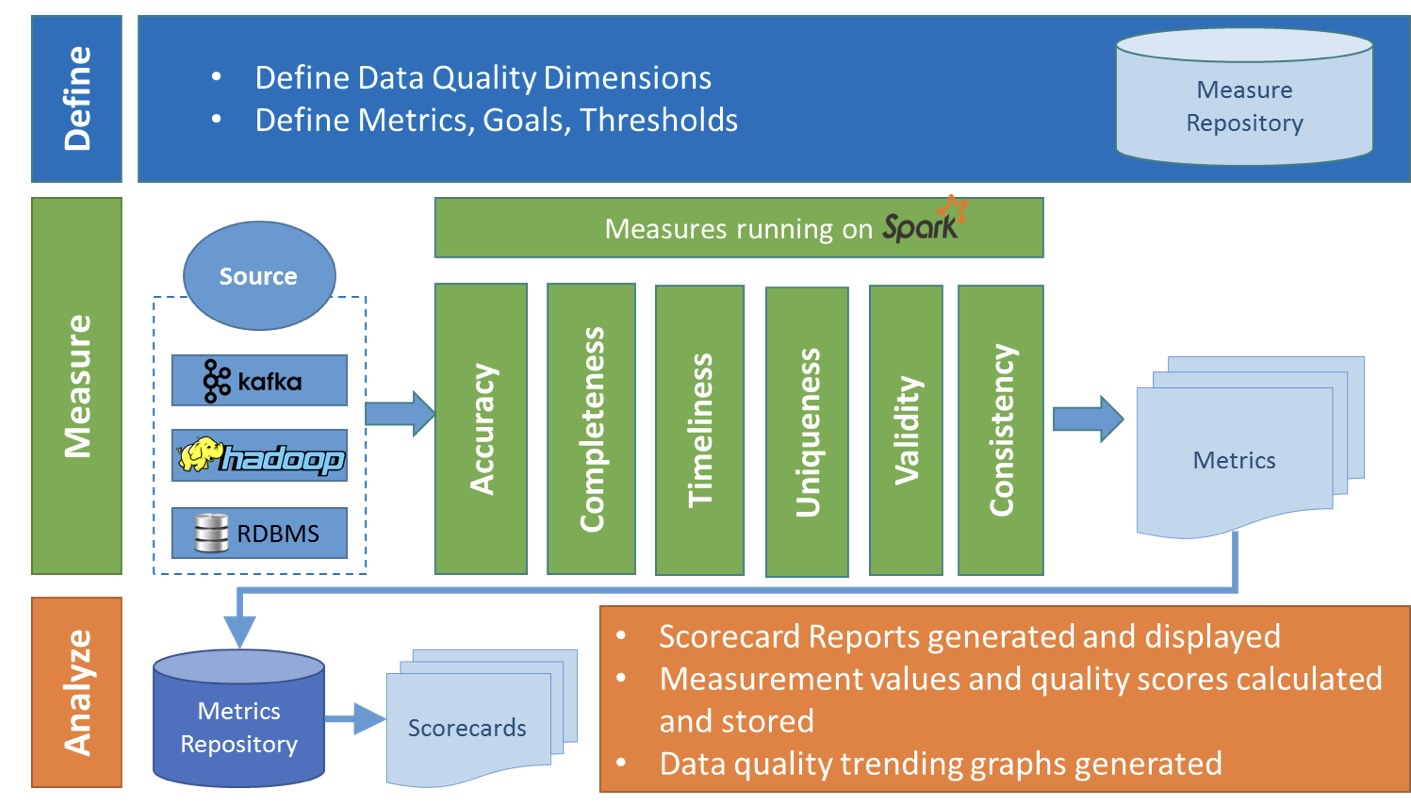
- Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)
- Measure:主要负责执行统计任务,生成统计结果
- Analyze:主要负责保存与展示统计结果
依赖环境:
- JDK (1.8 or later versions)
- MySQL(version 5.6及以上)
- Hadoop (2.6.0 or later)
- Hive (version 2.x)
- Spark (version 2.2.1 、2.4.4)
- Livy()
- ElasticSearch (5.0 、6.4.1)
源码:
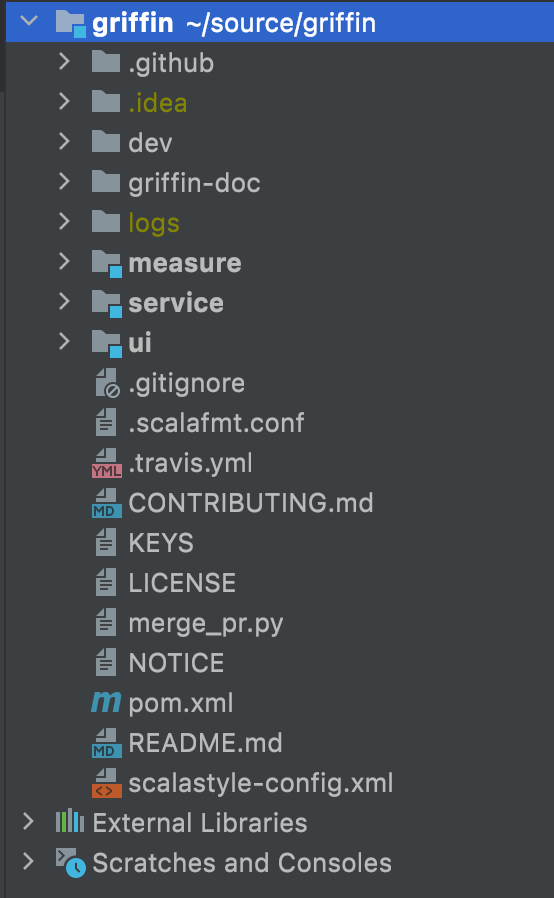
Griffin的源码结构很清晰,主要包括griffin-doc、measure、service和ui四个模块,其中griffin-doc负责存放Griffin的文档,measure负责与spark交互,执行统计任务,service使用spring boot作为服务实现,负责给ui模块提供交互所需的restful api,保存统计任务,展示统计结果。
特点:
- 每个Measure执行会返回不符合质量规则的数据(badRecordsDf)和质量评估结果(metricDf)两个数据表。
- 基于Spark引擎,支持批处理和流模式两种数据质量检测方式,流模式支持Kafka。
- 多种数据源支持通过connector实现,分为batch和streaming,batch包括Hive、JDBC、Hive、File、ES、Cassandra等,streaming包括Kafka。
Griffin安装
Griffin-0.6.0安装。
依赖环境:MySQL、hadoop2.7、spark2.2.1、hive、livy、es。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
# http://griffin.apache.org/docs/quickstart-cn.html
# https://github.com/apache/griffin/blob/master/griffin-doc/deploy/deploy-guide.md
# 下载
wget https://downloads.apache.org/griffin/0.6.0/griffin-0.6.0-source-release.zip
unzip griffin-0.6.0-source-release.zip
cd griffin-0.6.0
# 初始化
# 1.mysql创建quartz数据库并初始化
mysql -uroot < service/src/main/resources/Init_quartz_mysql_innodb.sql
# 2.hadoop和hive
hadoop fs -mkdir -p /home/spark_lib
hadoop fs -mkdir -p /home/spark_conf
hadoop fs -put $SPARK_HOME/jars/* /home/spark_lib/
hadoop fs -put $HIVE_HOME/conf/hive-site.xml /home/spark_conf/
# 3.service/src/main/resources/application.properties
# ===========================================================================
spring.datasource.url=jdbc:mysql://localhost:5432/quartz?autoReconnect=true&useSSL=false
spring.datasource.username=griffin
spring.datasource.password=*
spring.jpa.generate-ddl=true
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.show-sql=true
# Hive metastore
hive.metastore.uris=thrift://localhost:9083
hive.metastore.dbname=default
hive.hmshandler.retry.attempts=15
hive.hmshandler.retry.interval=2000ms
#Hive jdbc
hive.jdbc.className=org.apache.hive.jdbc.HiveDriver
hive.jdbc.url=jdbc:hive2://localhost:10000/
hive.need.kerberos=false
hive.keytab.user=xxx@xx.com
hive.keytab.path=/path/to/keytab/file
# Hive cache time
cache.evict.hive.fixedRate.in.milliseconds=900000
# Kafka schema registry
kafka.schema.registry.url=http://localhost:8081
# Update job instance state at regular intervals
jobInstance.fixedDelay.in.milliseconds=60000
# Expired time of job instance which is 7 days that is 604800000 milliseconds.Time unit only supports milliseconds
jobInstance.expired.milliseconds=604800000
# schedule predicate job every 5 minutes and repeat 12 times at most
#interval time unit s:second m:minute h:hour d:day,only support these four units
predicate.job.interval=5m
predicate.job.repeat.count=12
# external properties directory location
external.config.location=
# external BATCH or STREAMING env
external.env.location=
# login strategy ("default" or "ldap")
login.strategy=default
# ldap
ldap.url=ldap://hostname:port
ldap.email=@example.com
ldap.searchBase=DC=org,DC=example
ldap.searchPattern=(sAMAccountName={0})
# hdfs default name
fs.defaultFS=
# elasticsearch
elasticsearch.host=localhost
elasticsearch.port=9200
elasticsearch.scheme=http
# elasticsearch.user = user
# elasticsearch.password = password
# livy
livy.uri=http://localhost:38998/batches
livy.need.queue=false
livy.task.max.concurrent.count=20
livy.task.submit.interval.second=3
livy.task.appId.retry.count=3
livy.need.kerberos=false
livy.server.auth.kerberos.principal=livy/kerberos.principal
livy.server.auth.kerberos.keytab=/path/to/livy/keytab/file
# yarn url
yarn.uri=http://localhost:38088
# griffin event listener
internal.event.listeners=GriffinJobEventHook
logging.file=logs/griffin-service.log
# ===========================================================================
# 编译打包
mvn clean install
# change jar name
mv measure-0.6.0.jar griffin-measure.jar
# upload measure jar file
hadoop fs -mkdir -p /griffin/
hadoop fs -put griffin-measure.jar /griffin/
# es索引创建
POST griffin/accuracy
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": {
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
},
"type": "text"
},
"tmst": {
"type": "date"
}
}
}
}
模块详情
- 调度:quartz
- 质量任务执行:spark
- spark任务提交:livy
- 质量报告查询:es
Define
准确性
添加measure:基本信息、数据源表信息(source、target)、规则。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
{
"measure.type": "griffin",
"id": 1,
"name": "t1_t2",
"owner": "test",
"deleted": false,
"dq.type": "ACCURACY",
"sinks": [
"ELASTICSEARCH",
"HDFS"
],
"process.type": "BATCH",
"data.sources": [
{
"id": 4,
"name": "source",
"connector": {
"id": 5,
"name": "source1635859760697",
"type": "HIVE",
"version": "1.2",
"predicates": [],
"data.unit": "1day",
"data.time.zone": "",
"config": {
"database": "default",
"table.name": "t1"
}
},
"baseline": false
},
{
"id": 6,
"name": "target",
"connector": {
"id": 7,
"name": "target1635859764784",
"type": "HIVE",
"version": "1.2",
"predicates": [],
"data.unit": "1day",
"data.time.zone": "",
"config": {
"database": "default",
"table.name": "t2"
}
},
"baseline": false
}
],
"evaluate.rule": {
"id": 2,
"rules": [
{
"id": 3,
"rule": "source.id=target.id AND source.t1_c1=target.t2_c1 AND source.t1_c2=target.t2_c2 AND source.t1_c3=target.t2_c3",
"dsl.type": "griffin-dsl",
"dq.type": "ACCURACY",
"out.dataframe.name": "accuracy"
}
]
},
"measure.type": "griffin"
}
配置job:关联measure id、调度信息、数据源切片segments。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
{
"job.type": "batch",
"id": 366,
"measure.id": 1,
"job.name": "test_job_01",
"metric.name": "test_job_01",
"quartz.name": "test_job_01_1635995107730",
"quartz.group": "BA",
"cron.expression": "0 */2 * * * ?",
"cron.time.zone": "GMT+8:00",
"predicate.config": null,
"data.segments": [
{
"id": 367,
"data.connector.name": "source1635859760697",
"as.baseline": true,
"segment.range": {
"id": 368,
"begin": "-1day",
"length": "1day"
}
},
{
"id": 369,
"data.connector.name": "target1635859764784",
"as.baseline": false,
"segment.range": {
"id": 370,
"begin": "-1day",
"length": "1day"
}
}
],
"job.type": "batch"
}
数据统计
配置measure:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
{
"measure.type": "griffin",
"id": 357,
"name": "test_measure_profiling_t1",
"owner": "test",
"deleted": false,
"dq.type": "PROFILING",
"sinks": [
"ELASTICSEARCH",
"HDFS"
],
"process.type": "BATCH",
"rule.description": {
"details": [
{
"name": "id",
"infos": "Total Count"
},
{
"name": "t1_c1",
"infos": "Total Count"
},
{
"name": "t1_c2",
"infos": "Average"
},
{
"name": "t1_c3",
"infos": "Maximum"
}
]
},
"data.sources": [
{
"id": 360,
"name": "source",
"connector": {
"id": 361,
"name": "source1635994961662",
"type": "HIVE",
"version": "1.2",
"predicates": [],
"data.unit": "1day",
"data.time.zone": "",
"config": {
"database": "default",
"table.name": "t1",
"where": ""
}
},
"baseline": false
}
],
"evaluate.rule": {
"id": 358,
"rules": [
{
"id": 359,
"rule": "count(source.id) AS `id_count`,count(source.t1_c1) AS `t1_c1_count`,avg(source.t1_c2) AS `t1_c2_average`,max(source.t1_c3) AS `t1_c3_max`",
"dsl.type": "griffin-dsl",
"dq.type": "PROFILING"
}
]
},
"measure.type": "griffin"
}
配置job:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
"job.type": "batch",
"id": 362,
"measure.id": 357,
"job.name": "test_job_02",
"metric.name": "test_job_02",
"quartz.name": "test_job_02_1635995037192",
"quartz.group": "BA",
"cron.expression": "0 */2 * * * ?",
"cron.time.zone": "GMT+8:00",
"predicate.config": null,
"data.segments": [
{
"id": 363,
"data.connector.name": "source1635994961662",
"as.baseline": true,
"segment.range": {
"id": 364,
"begin": "-1day",
"length": "1day"
}
}
],
"job.type": "batch"
}
job执行,提交livy任务请求体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"file":"hdfs:///griffin/griffin-measure.jar",
"className":"org.apache.griffin.measure.Application",
"queue":"default",
"numExecutors":2,
"executorCores":1,
"driverMemory":"1g",
"executorMemory":"1g",
"conf":{
"spark.yarn.dist.files":"hdfs:///home/spark_conf/hive-site.xml"
},
"files":[
],
"args":[
"env环境配置",
"measure配置",
"raw,raw"
]
}
Measure
- AccuracyMeasure:准确性,两张表对比
- CompletenessMeasure:完整性(not null)
- DuplicationMeasure:重复值
- ProfilingMeasure:统计值
- SchemaConformanceMeasure:表字段数据类型
- SparkSQLMeasure:自定义SparkSQL
spark任务,通过传入的env配置和measure配置启动质量任务。评估结果写入hive持久化、写入ElasticSearch提供给web端查询。
AccuracyMeasure
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
{
"name": "accu_batch",
"process.type": "batch",
"data.sources": [
{
"name": "source",
...
},
{
"name": "target",
...
}
],
"evaluate.rule": {
"rules": [
{
"rule": "source.user_id=target.user_id AND source.first_name=target.first_name AND source.last_name=target.last_name",
"dsl.type": "griffin-dsl",
"dq.type": "ACCURACY",
"out.dataframe.name": "accuracy"
}
]
},
"sinks": [
"consoleSink",
"customSink"
]
}
解析后步骤:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 注册中间表:source、target、accuracy
# 1. miss record
SELECT `source`.*
FROM `source`
LEFT JOIN `target` ON coalesce(`source`.`user_id`, '') = coalesce(`target`.`user_id`, '') AND
coalesce(`source`.`first_name`, '') = coalesce(`target`.`first_name`, '') AND
coalesce(`source`.`last_name`, '') = coalesce(`target`.`last_name`, '')
WHERE (NOT (`source`.`user_id` IS NULL AND `source`.`first_name` IS NULL AND `source`.`last_name` IS NULL))
AND (`target`.`user_id` IS NULL AND `target`.`first_name` IS NULL AND `target`.`last_name` IS NULL);
# 2. miss count
SELECT COUNT(*) AS `miss` FROM `__missRecords`;
# 3. total count
SELECT COUNT(*) AS `total` FROM `source`;
# 4. accuracy metric
SELECT A.total AS `total`,
A.miss AS `miss`,
(A.total - A.miss) AS `matched`,
coalesce((A.total - A.miss) / A.total, 1.0) AS `matchedFraction`
FROM (
SELECT `__totalCount`.`total` AS total,
coalesce(`__missCount`.`miss`, 0) AS miss
FROM `__totalCount`
LEFT JOIN `__missCount`
) AS A;
SchemaConformanceMeasure
模式一致性确保给定数据集的属性在数据类型方面遵循一组标准数据定义。
大多数二进制文件格式(orc、avro 等)和表格源(Hive、RDBMS 等)已经对它们表示的数据施加了类型约束,但基于文本的格式(如 csv、json、xml 等)不保留架构信息。例如,客户的出生日期应该是一个日期,年龄应该是一个整数。
主要用于文本格式里数据schema检测。
1
2
3
4
5
6
7
val incompleteExpr = safeReduce(
givenExprs
.map(e =>
when(col(e.sourceCol).cast(StringType).cast(e.dataType).isNull, true)
.otherwise(false)))(_ or _)
// 将源列sourceCol转成StringType再尝试转成指定的数据类型dataType,以此来判断是否符合预期格式
执行结果(_METRICS和__missRecords)
如AccuracyMeasure执行完成,在HDFS查看结果:包含_METRICS评估结果、__missRecords不合格数据记录。

_METRICS评估结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{
"name": "test_job_02",
"tmst": 1635840720000,
"value": {
"total": 2,
"miss": 1,
"matched": 1,
"matchedFraction": 0.5
},
"metadata": {
"applicationId": "application_1635924847788_0013"
}
}
__missRecords不合格数据记录:
{
"id": 2,
"col1": 2,
"__tmst": 1635840720000
}
Analyze
直接查询ES。
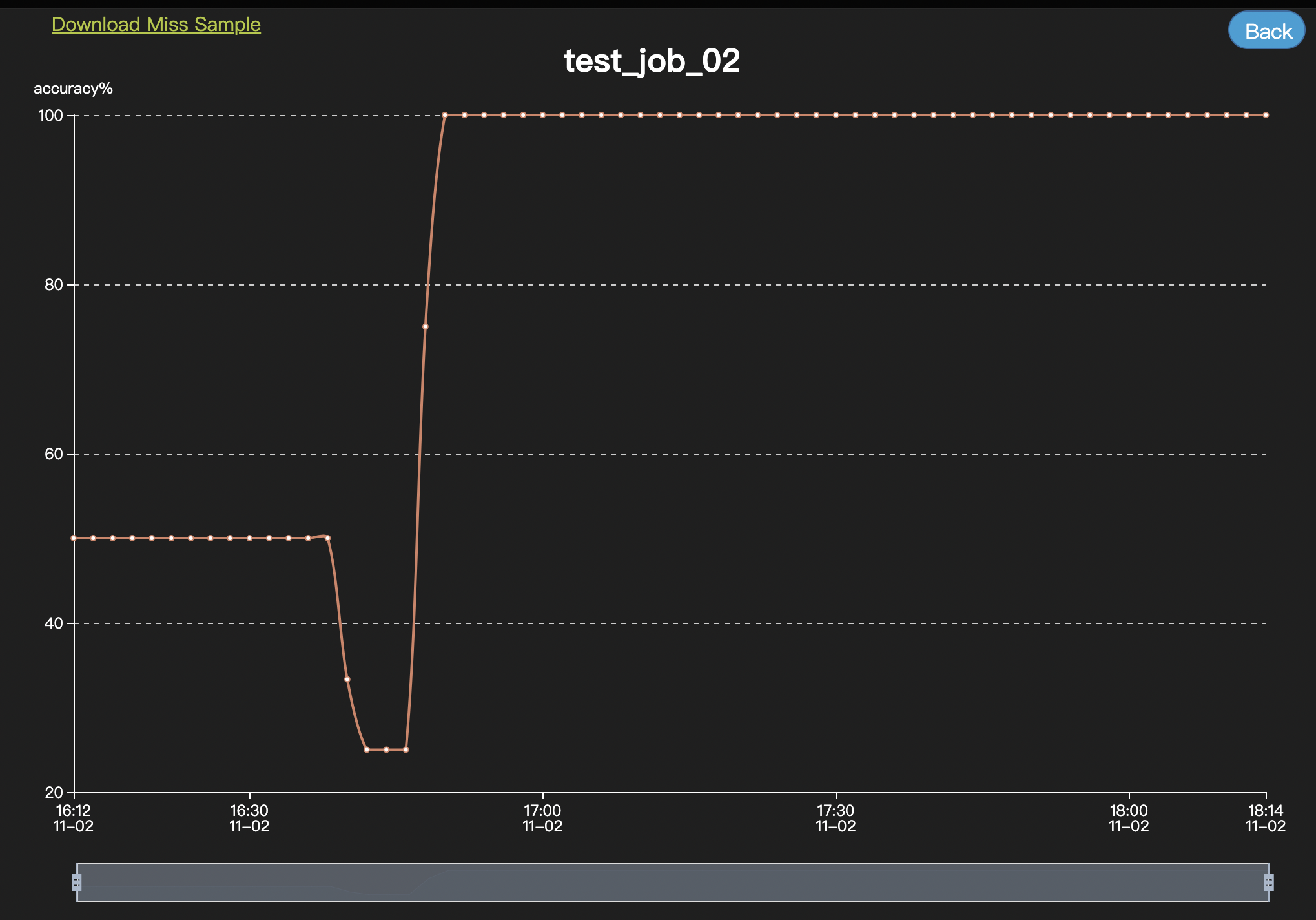
自定义sql
spark-sql。
总结
优点:
- 基于Spark引擎,支持批处理和流模式两种数据质量检测方式,流模式支持Kafka。
- 多种数据源支持通过connector实现,分为batch和streaming,batch包括Hive、JDBC、Hive、File、ES、Cassandra等,streaming包括Kafka。
- 支持自定义spark sql。
缺陷:
- 没有告警配置,只是各个规则执行结果的展示。
- 预定义规则有限。
- 界面配置仅支持Accuracy、Profiling,自定义需要通过完整json或yaml配置。