Ray
简介
Ray provides a simple, universal API for building distributed applications.
Ray 是一个用于快速、简单构建和运行分布式应用的框架。
Ray 是继 Spark 之后由 UC Berkeley AMP 实验室又推出一重磅高性能 AI 计算引擎,它在设计时主要是为了解决在 Reinforcement Learning(RL,强化学习)场景下遇到的一些问题。
Ray提供的能力
- Dynamic task graph:相比于 Spark、Flink,Ray 可以支持动态 Graph,这个让 Ray 具有了 FAAS 的一些能力,使得 Ray 的扩展性比较强;
- Stateless tasks and actors combined:Ray 提供了 task(无状态)模型和 Actor(有状态)模型的统一抽象,做到了支持有状态和无状态的计算;
- Shared object store with zero copy deserialization:每个节点通过共享存储维护了一块局部的对象存储,并且利用专门的 Apache Arrow 格式来进行不同节点间的数据交换;
- Bottom-up scheduling for low latency:Ray 在实现时,调度部分分为本地调度器和全局调度器,通过这种方式 Ray 可以做到每秒百万级 task 调度(声称);
- Clean Python API:Ray 本就是为了解决 RL 的问题而设计,一开始就选择了 Python 作为对外的接口。
Ray API
- ray.init():在 PythonShell 中,使用 ray.init() 可以在本地启动 ray,包括 Driver、HeadNode(Master)和若干 Slave;
- @ray.remote:在 python 中使用这个注解表示声明了一个 remote function,它是 Ray 的基本任务调度单元,它在定义后,会被立马序列化存储到 RedisServer 中,并且分配一个唯一的 ID,这样就能保证集群所有节点都能看到这个函数的定义;
- ray.put():将 python 对象存储本地 ObjectStore 中,并且异步返回一个唯一的 ObjectID,通过这个 ID,Ray 可以访问集群中任何一个节点上的对象;
- ray.get():使用这个方法可以通过 ObjectID 获取 ObjectStore 内的对象并将之转换为 Python 对象,这个方法是阻塞的,会等到结果返回;
- ray.wait():操作支持批量的任务等待,基于此可以实现一次性获取多个 ObjectID 对应的数据;
- ray.error_info():使用 ray.error_info() 可以获取任务执行时产生的错误信息;
Ray Function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import ray
# 本地启动 ray,如果想指定已有集群,在 init 方法中指定 RedisServer 即可
ray.init()
# 可以声明一个 remote function;
# remote 函数是 Ray 的基本任务调度单元,remote 函数定义后会立即被序列化存储到 RedisServer中,并且分配了一个唯一的 ID,这样就保证了集群的所有节点都可以看到这个函数的定义
@ray.remote
def f1(x):
return x * x
@ray.remote
def f2(y):
return y + 10
@ray.remote
def f3(x, y):
return x + y
# 这里拿到的都是 future,相当于异步调用,只要调用 get 接口才会去拿计算的结果;通过 function.remote() 的方式调用这个函数
# 这里的 x/y 实际上拿到的都是 Object IDs
x = f1.remote(2)
y = f2.remote(3)
# remote function 可以组合在一起使用
z = f3.remote(x, y)
# get 接口可以通过 ObjectID 获取 ObjectStore 内的对象并将之转换为 Python 对象
# get 接口在调用时会阻塞,知道获取结果
print(ray.get(z))
####### 输出结果 ########
17
Ray Actor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import ray
ray.init()
# 在 Python 的 class 定义前使用 @ray.remote 来声明 Actor
# actor 会记录相应的状态
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
# 使用 Class.remote() 创建 actor
counters = [Counter.remote() for i in range(4)]
# 使用 actor.function.remote() 调用 actor 的方法,其他与普通的 remote function 就很类似了
# 这里的 features 也是 Object IDs;
futures = [c.read.remote() for c in counters]
print(ray.get(futures))
futures = [c.read.remote() for c in counters]
print(ray.get(futures))
futures = [c.read.remote() for c in counters]
print(ray.get(futures))
############# 输出结果 #########
# 这里调用三次,可以看到对应 actor 的状态是有记录的
[1, 1, 1, 1]
[2, 2, 2, 2]
[3, 3, 3, 3]
Ray原理
Ray架构
Ray 在设计上也是使用了 Master-Slave 架构,Master(head node) 节点负责全局协调和状态维护,Slave(worker node) 负责具体的任务执行,Ray 架构图如下所示
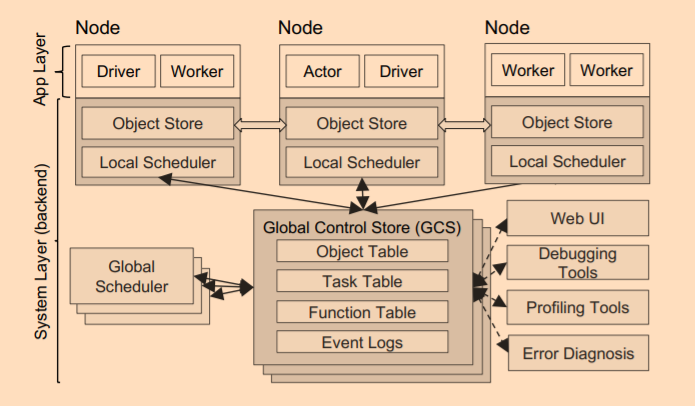
- GlobalScheduler:Master 上启动了一个全局调度器,用户与接收 LocalScheduler 提交的任务,并将任何分配给合适的 Node 执行;
- GlobalControlStore(GCS):它维护整个集群的状态信息,与其他系统的区别是它的 Scale 能力,它可以做到独立部署,并且横向扩展,官方默认是把这个状态信息储存到 Redis 中;
- LocalScheduler(raylet):每个 Node 上启动了一个 LocalScheduler,用于提交任务到 GlobalScheduler 以及分配任务到当前 Node 的 worker 进程上;
- Worker:每个 Node 上可以启动多个 Worker 进程执行分布式任务,并将计算结果保存到 ObjectStore 中;
- ObjectStore:每个 Node 上启动了一个 ObjectStore 存储只读对象,Node 的 worker 之间通过共享内存的方式访问这些对象数据;
- Plasma:每个 Node 上的 ObjectStore 都是由 Plasma 来管理,它可以在 worker 访问本地不存在的远程数据对象时,主动拉取其他 Node 上的对象到本地机器。
在提交作业上,Ray 的设计与 Spark 有些类似,都是通过 Driver 提交的,Driver 可以运行在本地(打开 Python Shell 运行 Ray 作业)、也可以运行在 Node 上(作为一个 worker 运行)。
Task 和 Actor
在 RL 场景中,它既需要无状态、短暂的计算模式,又需要有状态、长时连续运行的计算模式,Ray 在设计时,就考虑了同时满足这两种需求,因此,Ray 在计算模型上提供了对 Task 和 Actor 的统一抽象。Task 应用于无状态的计算,它的容错及 load balance 都比较简单;Actor 应用于有状态的计算,它的容错和 load balance 就复杂了一些。
有状态的计算,根据调用有顺序地进行计算,无需加锁(这个也是 Actor 模型的特点)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 通过 Python class 注册一个 Actor
@ray.remote
class ParameterServer(object):
def __init__(self, keys, values):
values = [value.copy() for value in values] self.weights = dict(zip(keys, values))
def push(self, keys, values):
for key, value in zip(keys, values):
self.weights[key] += value
def pull(self, keys):
return [self.weights[key] for key in keys]
# 初始化这个 actor
ps = ParameterServer.remote(keys, initial_values)
# 执行这个 actor 的相关方法
# actor 方法调用是顺序执行的,这个模型非常简单,不会有加锁相应的操作
future0 = ps.push.remote(keys, grads0)
future1 = ps.push.remote(keys, grads1)
future2 = ps.grab.pull(keys)
Remote Task exectute
一个 Task 是如何调度运行(a 存储在 Node N1 上,b 存储在 Node N2 上):
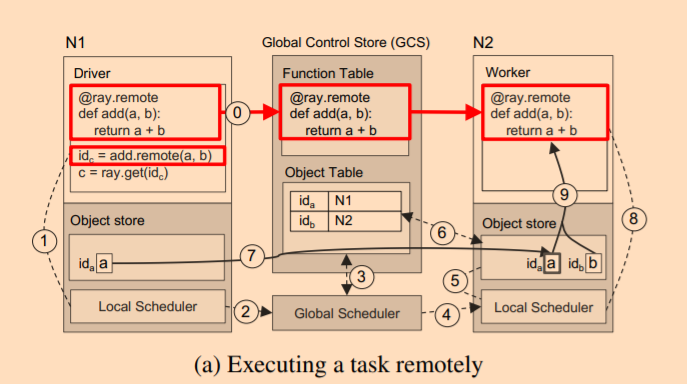
其执行步骤如下(在图中的第 0 步中,它会先将 add 函数注册到 GCS 中):
- 执行
id = add.remote(a,b)函数,先往 Local Scheduler 进行调度; - Local Scheduler 发现本地只有
a,没有b,向 Global Scheduler 求助; - Global Scheduler 查询 GCS 中的 Object Table 获取
b的位置; - Global Scheduler 决定将这个 task 调度到
b所在节点 N2; - N2 的 Local Scheduler 发现本地没有
a; - N2 向 GCS 中的 Object Table 查询
a的位置; - N2 从
a的 Object Store 中拷贝到本地的 Object Store; - 执行函数;
而调用 get 结果获取执行结果的流程如下图:
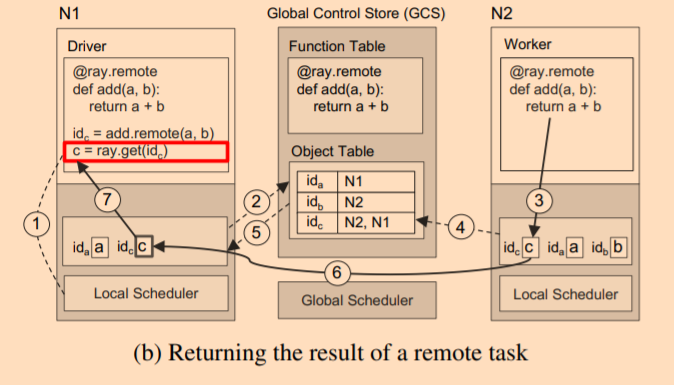
- 使用
c的 feature 请求 local object store; - 由于 N1 的 local object store 没有
c的缓存,它会向 GCS 求助,但是此时c的计算还没完成,因此 N1 的 Object store 会在 GCS 的 Object Table 中注册一个callback,当c的结果完成后会通知 N1 的 Object Store; - 此时,N2 完成计算逻辑,它会把
c存储到 N2 的 Local Object Store 中; - N2 的 Local Object Store 在存储
c时,也会把结果同步到 GCS,告诉 GCSc的结果现在存储在 N2 节点中; - GCS 触发 N1 Object Store 存储的
callback; - N1 从 N2 节点将
c拷贝过来; - 返回结果;
容错机制
它的容错是基于 GCS 存储的状态来做的,可以分为以下两种情况:
- Non Actors:根据血缘关系重新构造上下游关系,直接恢复即可;
- Actors:就需要依赖 Checkpoint 及数据重放来恢复了。
调度实现
Ray 的一个目标是实现每秒百万级任务调度,为此设计了两级调度器,包括全局调度器和每个节点上的本地调度器(raylet)。为了降低全部调度器的负载,节点 (worker,actor) 上派生的任务首先提交给 LocalScheduler,如果本地的资源无法满足,则会把待调度的任务提交给 GlobalScheduler。
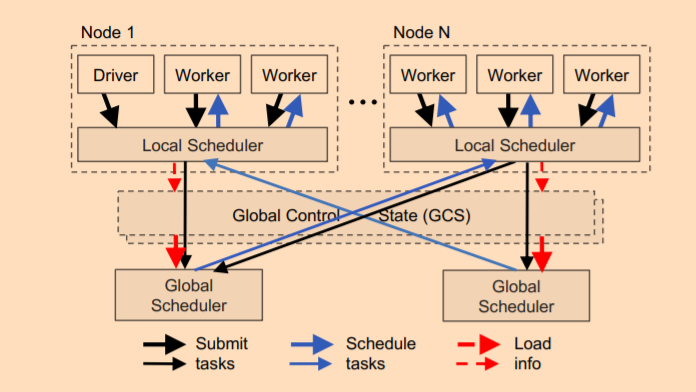
GlobalScheduler 会根据每个节点的负载和任务的需求进行调度。决策依据有:
-
- 每个 Node 上任务队列的大小;
-
- Node 上任务的排队时间;
-
- 任务需要的数据传输到该节点所需的时间;
当 GlobalScheduler 出现瓶颈时,Ray 会实例化更多的 GlobalScheduler 来分担工作,这得益于 GCS,使得 GlobalScheduler 可扩展。