MapReduce流程解析
介绍了MapReduce的详细流程和一些总结.
MapTask流程图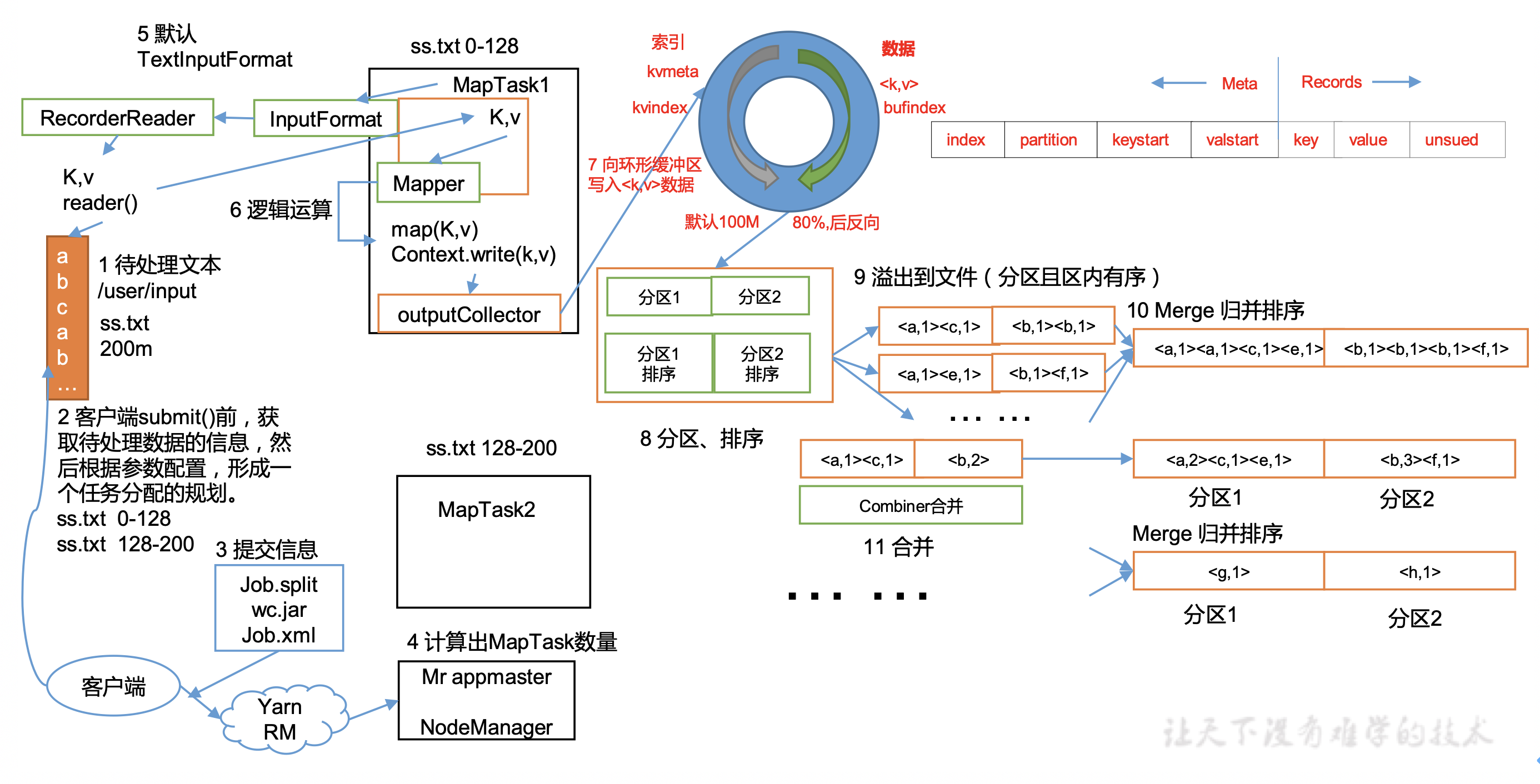
ReduceTask流程图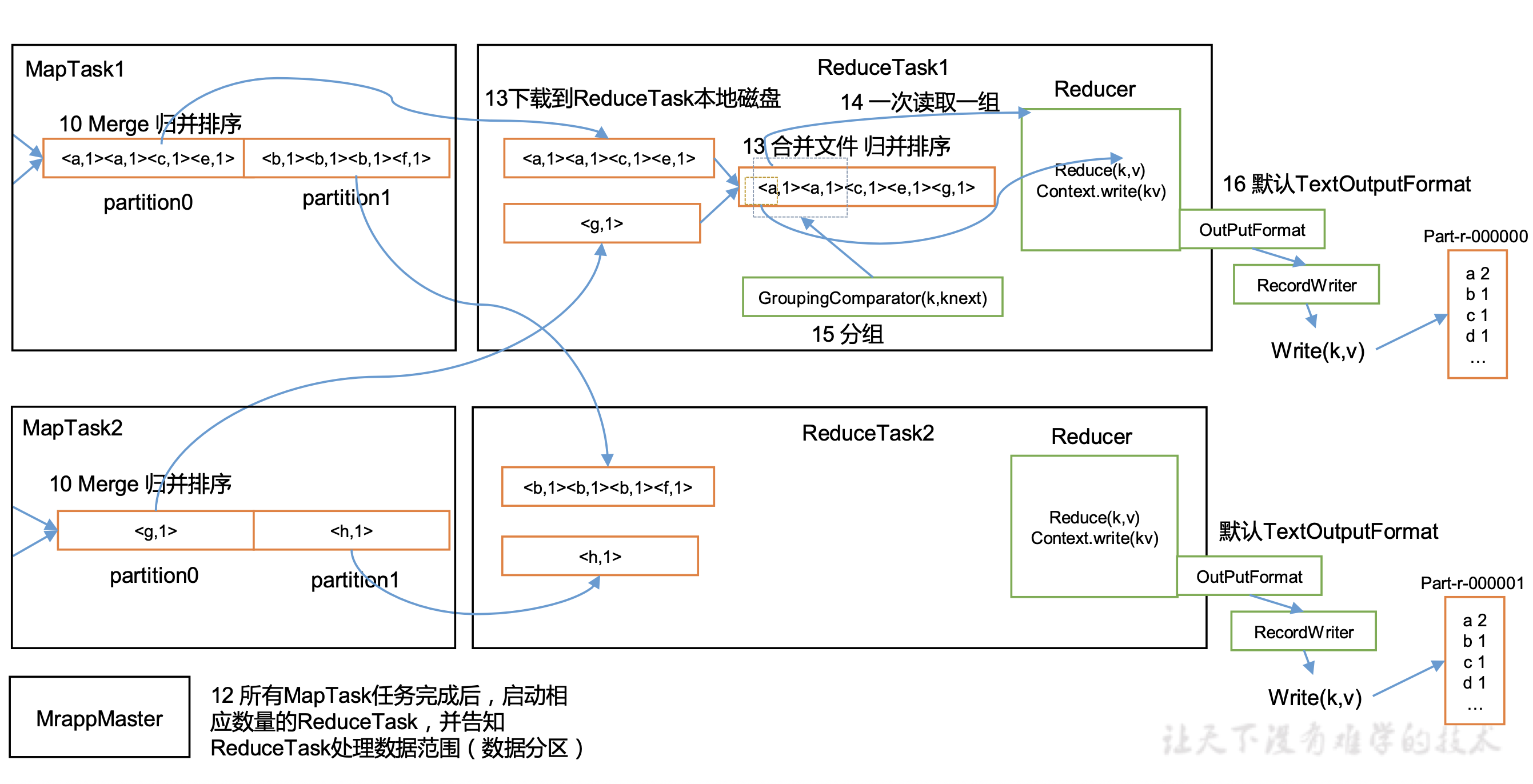
Shuffer流程图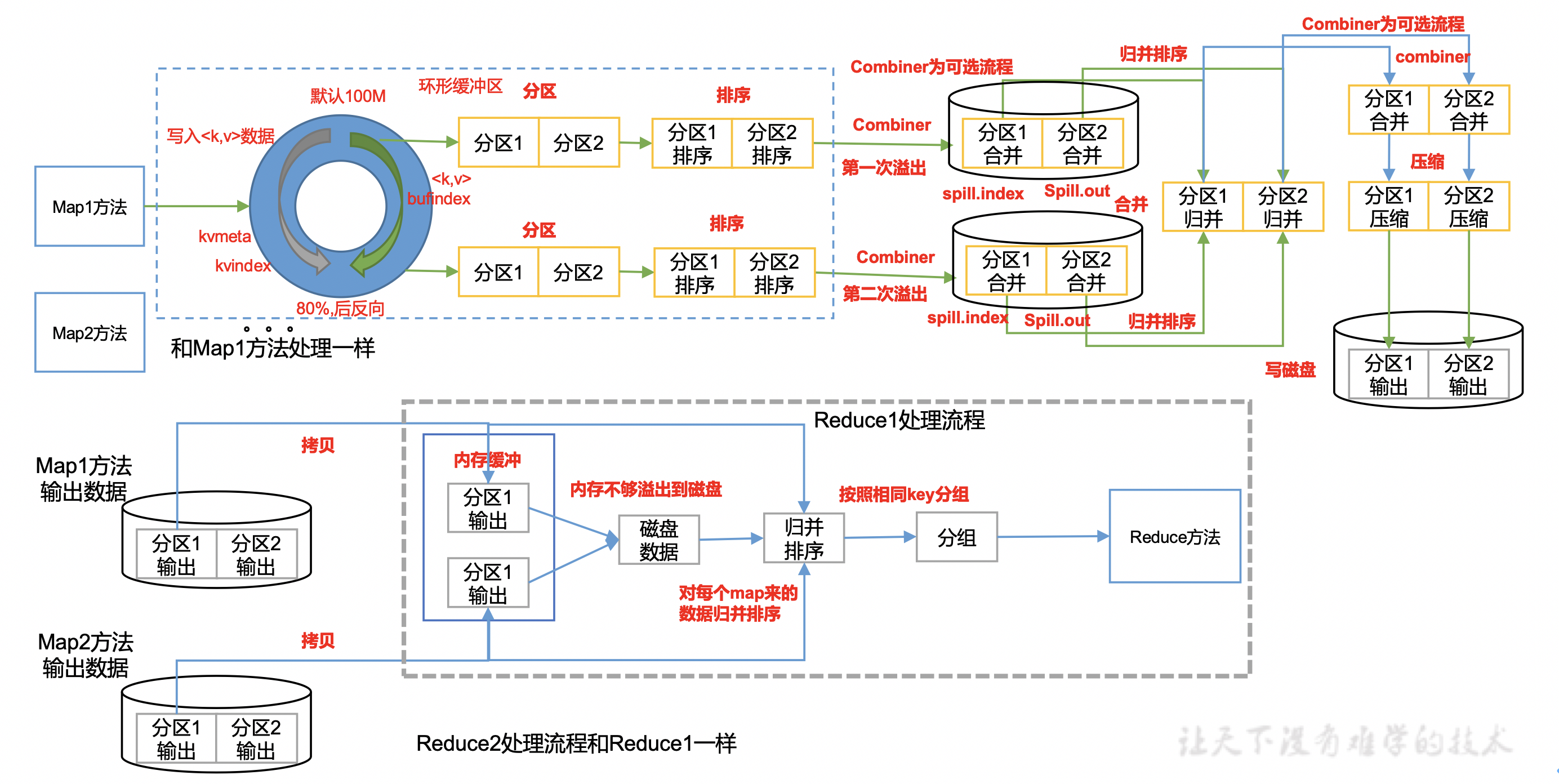
具体步骤
逻辑上可以这样划分:1-10是MapTask ;11-16是ReduceTask;7-14是shuffer
1. 待处理文本
这里假设是/user/input目录下的ss.txt 文件,大小为200M。
2. 客户端submit()
发生在client端,主要获取3个信息:
(1)Job.split :找到文件ss.txt,根据切片算法,得到切片的元数据信息(起始位置,长度以及所在节点等)如把ss.txt分成两片 0-128M 和 128M-200M
(2)Job.xml:任务的配置信息
(3)wc.jar:任务的jar包
(可以在/tmp/hadoop-zxy/mapred/staging/zxy1248702679/.staging/下找到它们)
3. 提交信息
将刚刚获取的任务规划信息,提交到资源管理器上,这里用Yarn。
4. RM计算MapTask数量
接着向Yarn的RM申请资源,RM根据任务规划信息用户Job分成Task,并把任务下发给节点。这里我们数据分成了2片,根据默认规则,会有2个MapTask各自处理一片数据。
5. 根据采用的InputFormat读取数据
这里采用默认的TextInputFormat类,按行读取每条记录。key是行偏移量,value是该行的内容。
6. 执行Mapper的map()
根据用户的代码执行map逻辑,把结果写入Context中。
7. 向环形缓存区写入数据
环形缓存区取一点:一边写索引,一边写真实数据。达到80%时发生溢写
8. 分区、排序
一种2次排序,先按区号排,再对key排序(快排)。得到一组按区排好序的数据。注意:这步是在环形缓存区就可以执行的,且排序排的是索引,真实数据不用动。且此时可以使用第一次Combiner合并操作。
9. 溢出写入文件
环形缓存区达到80%时,溢写到磁盘上。注意写磁盘前已经完成了分区、排序、合并、压缩等操作。此时生成第一组溢写文件spillN.out 与元数据spillN.out.index。
10. MapTask的归并排序
将多组溢写文件,以分区为单位进行归并排序,写入磁盘形成大文件output/file.out,与索引文件output/file.out.index。此时一个MapTask任务完成,得到一个分区有序的数据。注意:在归并排序时可以使用第二次Combiner合并操作。
11. 启动ReduceTask
假设分区数为2,此时启动2个ReduceTask,一个ReduceTask处理一个区的数据。
12. copy数据
ReduceTask从各个MapTask上拷贝它要处理的区的数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
13. ReduceTask的归并排序
把同区的数据复制到同一个ReduceTask后,对它们进行归并排序
14. 分组
默认把key相同的数据分到一组。用户可以继承WritableComparator,自定义分组规则。
15. 执行Reducer的Reduce()
根据用户的代码执行reduce逻辑,把结果写入Context中。注意:一次读一组,value是迭代器对象,包含一个组的全部数据。
16. 根据采用的OutputFormat读取数据
这里采用默认的TextOutputFormat类,按行写入key和value,key和value用tab分开。
一些总结
1个逻辑
先分区 -> 再排序 -> 再分组
分区:用户定义分区数后,默认按hash分区。用户也可以继承Partitioner,自定义分区规则。ReduceTask的个数一般等于分区数。
排序:默认对key排序,key必须实现WritableComparable接口。用户可以重写WritableComparable接口的compareTo()方法,定义自己的排序规则。
分组:默认把key相同的数据分到一组。用户也可以继承WritableComparator,自定义分组规则。用于reduce阶段,一次读取一组.
2次合并
Combiner的父类就是Reducer,它可以通过对Map阶段的局部结果进行汇总,减少输出。
时机: 2次,分区排序后、MapTask的归并排序时。
条件:不能影响业务逻辑 且 输入输出的范型一致
3次排序
MapTask:
分区排序:在缓行缓冲区进行,是一种2次排序。先按分区号排序,再对key排序(快排)。
归并排序:对每组溢写的数据,进行的按区,归并排序。
ReduceTask:
归并排序:对从MapTask拷贝的同区数据,进行的归并排序。
分片和分区
分片:分片数决定MapTask的个数。在客户端即完成,举FileInputFormat切片机制为例:简单的按文件长度进行切片,切片大小等于块大小(默认128M),切片时是对文件单独切片。
分区:分区数决定ReduceTask的个数。