Presto
简介
Presto是一种用于大数据的高性能分布式SQL查询引擎。 其架构允许用户查询各种数据源,如Hadoop、AWS S3、Alluxio、MySQL、Cassandra、Kafka和MongoDB。 甚至可以在单个查询中查询来自多个数据源的数据。Presto是Apache许可证下发布的社区驱动的开源软件。
Presto是由Facebook开发的一个分布式SQL查询引擎, 它被设计为用来专门进行高速、实时的数据分析。 它的产生是为了解决Hive的MapReduce模型太慢以及不能通过BI或Dashboards直接展现HDFS数据等问题。 Presto是一个纯粹的计算引擎,它不存储数据,其通过Connector获取第三方Storage服务的数据。
历史:
- 2012年秋季,Facebook启动Presto项目
- 2013年冬季,Presto开源
- 2017年11月,11888 commits,203 releases,198 contributors
功能和优点:
- Ad-hoc,期望查询时间秒级或几分钟;
- 比Hive快10倍;
- 支持多数据源,如Hive、Kafka、MySQL、MonogoDB、Redis、JMX等,也可自己实现Connector;
- Client Protocol: HTTP+JSON, support various languages(Python, Ruby, PHP, Node.js Java);
- 支持JDBC/ODBC连接;
- ANSI SQL,支持窗口函数,join,聚合,复杂查询等;
应用场景:
Presto应用场景中,主要还是查询时延要求在毫秒或者秒级别的SQL并发BI报表,Ad-Hoc查询以及多数据源关联查询居多, 用Presto来做ETL工具的不多,毕竟Spark,Flink这些成熟的流批计算工具,用作ETL工具相对更成熟一些。
prestodb和prestosql:
PrestoDB是2013年Facebook的三个核心工程师创造和开源出来的,在Facebook内部,它的应用规模是很庞大的(部署了多个集群,总节点数10000+台), 这三个工程师一直想把Presto发扬光大,但是一直到了2019年,他们感觉到公司好像不怎么给力, 同时期的三个开源大数据技术Spark、Flink、Kafka都已经创建了自己的商业化公司推广到家喻户晓了, 如果说哪家公司在力推Presto,可能只有一家叫Teradata的小公司。
无奈之下,这三位核心工程师离职加入了刚成立两年的Starburst公司,这家公司Fork了Presto的项目源码,取名为PrestoSQL, 创建了自己的代码仓库和官方网站,在做商业化运营的Presto。
如果你问笔者该选哪个,笔者更倾向于选择PrestoSQL,因为他近两年的源码迭代速度更快,而且还有三位创始人的支持,相信PrestoSQL的发展前景。 不过事情也不是绝对的,PrestoDB与PrestoSQL也在互相学习,并且会把对方比较好的实现,merge到自己的项目里,所以同时关注一下这两个项目的动态,没有坏处。
架构与原理
基本架构
- Master-Slave架构
- 三个模块:
- Coordinator、Discovery Service、Worker
- Connector
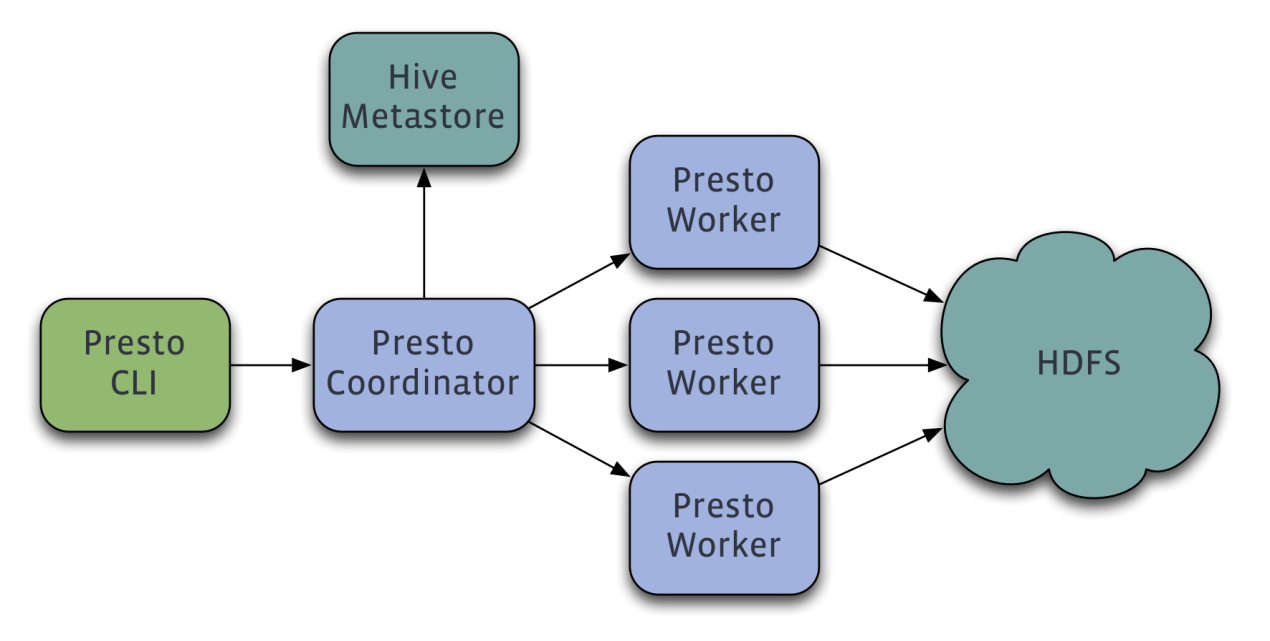
Presto沿用了通用的Master-Slave架构,Coordinator即Presto的Master,Worker即其Slave, Discovery Service就是用来保存Worker结点信息的,通过HTTP协议通信,而Connector用于获取第三方存储的Metadata及原始数据等。
- Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行;
- Worker节点负责实际执行查询任务;
- Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点;
- 假如配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
Presto的架构实际上就是一套分布式的SQL执行架构,它最大的特点就是天然就是存储计算分离,Presto只负责计算,存储的部分由数据源自身提供。 这种存储与计算分离的架构很符合当今云计算发展的趋势——独立的存储云服务与计算云服务,这样做的好处是存储资源不够时可以独立扩容存储,计算资源不够时可以独立扩容计算, 而且计算和存储能够分别使用适合自己的机型。
分布式的存储系统的实现一般都比较复杂,涉及到数据的分区、副本、容灾、文件格式、IO优化等,是一项非常大的工程。 Presto直接放弃了存储,只做计算,而且它的计算也是做了一些妥协的,如不支持单个Query内部的执行容错,如果Query中的某个Task失败了,会导致整个Query失败。 这样实现起来更简单,代价是需要用户侧来重试。
查询过程
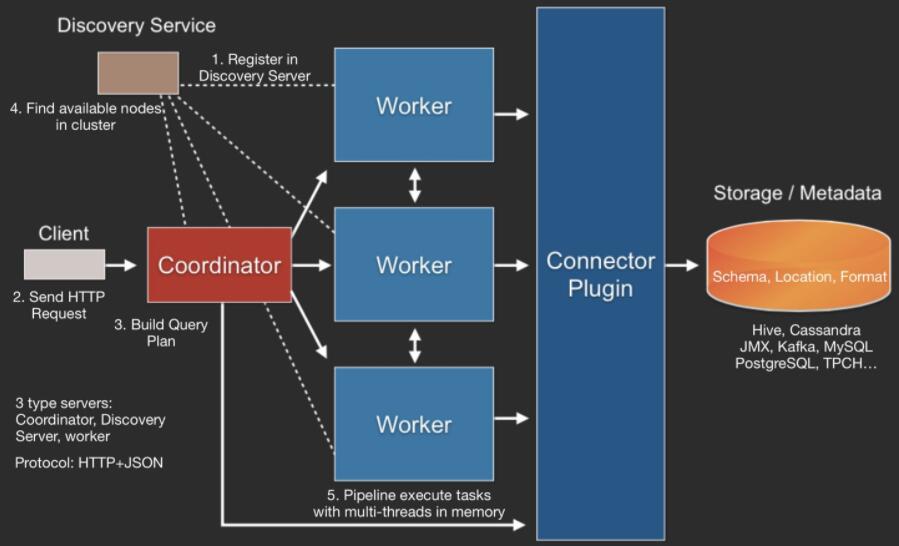
整体查询流程为:
- Client使用HTTP协议发送一个query请求;
- 通过Discovery Server发现可用的Server;
- Coordinator构建查询计划(Connector插件提供Metadata);
- Coordinator向workers发送任务;
- Worker通过Connector插件读取数据;
- Worker在内存里执行任务(Worker是纯内存型计算引擎);
- Worker将数据返回给Coordinator,之后再Response Client。
既然Presto是一个交互式的查询引擎,我们最关心的就是Presto实现低延时查询的原理,我认为主要是下面几个关键点,当然还有一些传统的SQL优化原理,这里不介绍了。
- 完全基于内存的并行计算;
- 流水线;
- 本地化计算;
- 动态编译执行计划;
- 小心使用内存和数据结构;
- 类BlinkDB的近似查询;
- GC控制;
SQL执行流程:
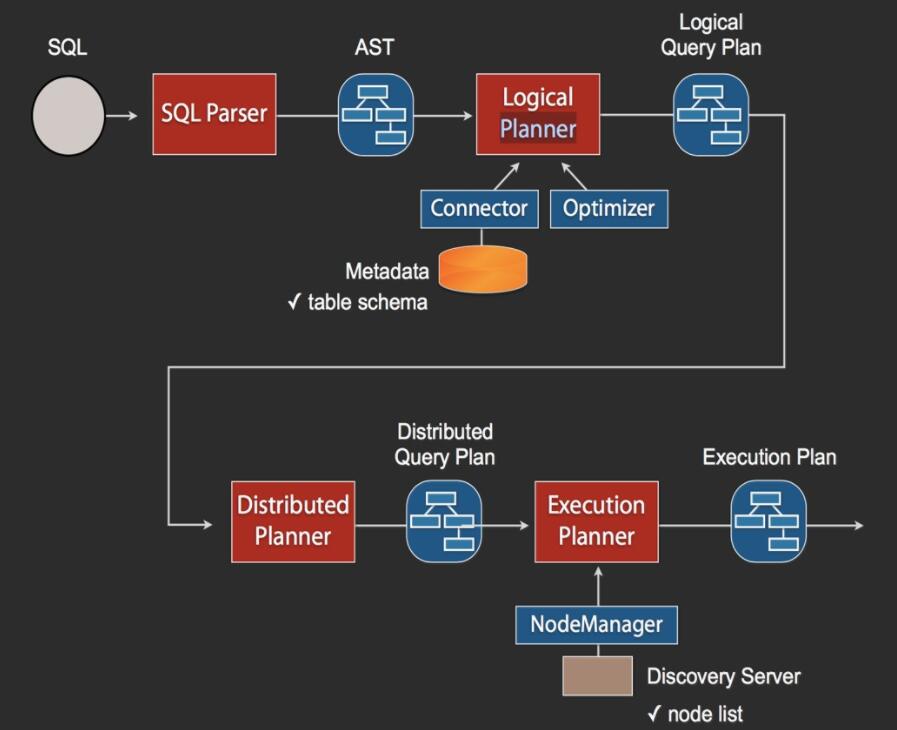
当Coordinator收到一个Query,其SQL执行流程如上图所示。
- SQL通过Anltr3解析为AST(抽象语法树),然后通过Connector获取原始数据的Metadata信息,这里会有一些优化,比如缓存Metadata信息等;
- 根据Metadata信息生成逻辑计划,然后会依次生成分发计划和执行计划;
- 在执行计划里需要去Discovery里获取可用的node列表,然后根据一定的策略,将这些计划分发到指定的Worker机器上,Worker机器再分别执行。
数据模型
Presto 使用 Catalog、Schema和Table 这3层结构来管理数据。如图:
.png)
- catalog:就是数据源。每个数据源连接都有一个名字,一个Catalog可以包含多个Schema;
- schema:相当于一个数据库实例,一个Schema包含多张数据表;
- table:数据表,与RDBMS上的数据库表意义相同。
在Presto中定位一张表,一般是catalog为根,例如:一张表的全称为 hive.test_data.test,标识hive(catalog)下的 test_data(schema)库中 test 表。
可以简理解为:数据源的类别.数据库.数据表。
可使用:show catalogs查看数据源;show schemas from hive查看数据库实例;show tables from default查看表。
切换当前使用的实例(在同一个数据源内切换无需指定catalog 前缀):use hive.default
Connector
Presto设计了一个简单的数据存储抽象层,来满足在不同数据存储系统之上都可使用sql进行查询。 存储插件(连接器connector)只需提供实现以下操作的接口,包括对元数据的获取,获得数据存储的位置,获取数据本身的操作。
- ConnectorMetadata: 管理表的元数据,表的元数据,partition等信息。在处理请求时,需要获取元信息,以便确认读取的数据的位置。Presto会传入filter条件,以便减少读取的数据的范围。元信息可以从磁盘上读取,也可以缓存在内存中。
- ConnectorSplit: 一个IO Task处理的数据的集合,是调度的单元。一个split可以对应一个partition,或多个partition。
- SplitManager : 根据表的meta,构造split。
- SlsPageSource : 根据split的信息以及要读取的列信息,从磁盘上读取0个或多个page,供计算引擎计算。
插件能够帮助开发者添加这些功能:
- 对接自己的存储系统;
- 添加自定义数据类型;
- 添加自定义处理函数;
- 自定义权限控制;
- 自定义资源控制;
- 添加query事件处理逻辑。
References
- 博客-armsword(滴滴Presto引擎负责人)
- PrestoDB和PrestoSQL比较及选择
- Presto实现原理和美团的使用实践
- Presto 在有赞的实践之路
- Presto在滴滴的探索与实践
- 分布式SQL查询引擎Presto原理介绍
- Presto Connector 实现原理