CSAPP-05优化程序性能
优化编译器的能力和局限性
编译器必须很小心地对程序只使用安全的优化。
例子1:
1
2
3
4
5
6
7
8
void twiddle1(long *xp, long *yp){
*xp += *yp;
*xp += *yp;
}
void twiddle2(long *xp, long *yp){
*xp += 2* *yp;
}
乍一看,这两个过程似乎有相同的行为。
另一方面,函数twiddle2效率更高一些,它只要求3次内存引用(读xp,读yp,写xp),而twiddle1需要6次(2次读xp,2次读yp,2次写xp)。因此,如果要编译器编译过程twiddle1,会认为基于twiddle2执行的计算能产生更有效的代码。
不过,考虑xp等于yp的情况:
1
2
3
4
5
6
// twiddle1(*xp, *xp) 结果是xp的值增加4倍
*xp += *xp;
*xp += *xp;
// twiddle2(*xp, *xp) 结果是xp的值增加3倍
*xp += 2* *xp;
因此,编译器不能产生twiddle2风格的代码作为twiddle1的优化版本。
这种两个指针指向同一个内存位置的情况称为内存别名使用(memory aliasing)。
例子2:
1
2
3
4
x = 1000; y = 3000;
*q = y; // 3000
*p = x; // 1000
t1 = *q; // 1000 or 3000; 要考虑*q和*p指针是否指向内存中同一个位置
第二个妨碍优化的因素是函数调用。
例子3:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
long f();
long func1(){
return f() + f() + f() + f();
}
long func2(){
return 4*f();
}
// 看上去两个过程计算的都是相同的结果,但是func2只调用f一次,而func1调用f四次。
// 加入f函数如下,那么:
// func1结果:0 + 1 + 2 + 3 = 6
// func2结果:4 * 0 = 0
long counter = 0;
long f(){
return counter++;
}
大多数编译器不会试图判断一个函数是否没有副作用。相反,编译器会假设最糟的情况,并保持所有的函数调用不变。
用内联函数替换(inline substitution)优化函数调用:将函数调用替换为函数体。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 内联函数 优化
long func1in(){
long t = counter++;
t += counter++;
t += counter++;
t += counter++;
return t;
}
// 这样的转换减少了函数调用的开销,也允许对展开的代码做进一步优化
// 编译器可以统一func1in中对全局变量counter的更新
long func1opt(){
long t = 4 * counter + 6;
counter += 4;
return t;
}
表示程序的性能
引入每元素的周期数(Cycles Per Element,CPE),作为一种表示程序性能并指导改进代码的方法。
程序示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
#include <stdio.h>
typedef long data_t;
// 创建一个vector向量数据结构
typedef struct
{
long len;
data_t *data;
} vec_rec, *vec_ptr;
// 创建一个特定长度的向量
vec_ptr new_vec(long len)
{
vec_ptr result = (vec_ptr)malloc(sizeof(vec_rec));
data_t *data = NULL;
if (!result)
{
return NULL;
}
result->len = len;
if (len > 0)
{
data = (data_t *)calloc(len, sizeof(data_t));
if (!data)
{
free((void *)result);
return NULL;
}
}
result->data = data;
return result;
}
// 获取向量里的某个元素并保存在 *dest
// return 0(out of bounds) or 1(successful)
int get_vec_element(vec_ptr v, long index, data_t *dest)
{
if (index < 0 || index >= v->len)
{
return 0;
}
*dest = v->data[index];
return 1;
}
// 返回向量的长度
long vec_length(vec_ptr v)
{
return v->len;
}
向量计算:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 对向量求和
#define IDENT 0
#define OP +
// 计算向量元素的乘积
#define IDENT 1
#define OP *
void combine1(vec_ptr v, data_t *dest)
{
long i;
*dest = IDENT;
for (int i = 0; i < vec_length(v); i++)
{
data_t val;
get_vec_element(v, i, &val);
*dest = *dest OP val;
}
}
消除循环的低效率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 1.消除循环的低效率:代码移动
void combine2(vec_ptr v, data_t *dest)
{
long i;
// 只计算一次length
long length = vec_length(v);
*dest = IDENT;
for (int i = 0; i < length; i++)
{
data_t val;
get_vec_element(v, i, &val);
*dest = *dest OP val;
}
}
减少过程调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 2.减少过程调用:
// get_vec_element函数里每次会对vec进行边界检查
// 所以用get_vec_start直接返回vec里的data数组,直接通过索引获取元素
// 但是,性能没有明显的提升。整数求和的性能还略有下降。
// 后面会探究为什么。
data_t *get_vec_start(vec_ptr v)
{
return v->data;
}
void combine3(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
*dest = IDENT;
for (int i = 0; i < length; i++)
{
*dest = *dest OP data[i];
}
}
消除不必要的内存引用
// 3.消除不必要的内存引用
// *dest = *dest OP data[i]; 累积变量的数值每次循环都要从内存读出再写入到内存
// 引入临时变量acc,在循环中累积计算出来的值,只在循环完成之后结果才放在dest中。
void combine4(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for (int i = 0; i < length; i++)
{
acc = acc OP data[i];
}
*dest = acc;
}
理解现代处理器
- 理解指令级并行;
- 延迟界限(latency bound);
- 吞吐量界限(throughput bound);
整体操作
超标量(superscalar):可以在每个时钟周期执行多个操作,而且是乱序的(out-of-order)。指令执行的顺序不一定要与它们在机器级程序中的顺序一致。
整个设计有两个主要部分:
- 指令控制单元(Instruction Control Unit,ICU):负责从内存中读出指令序列,并根据这些指令序列生成一组针对程序数据的基本操作。
- 执行单元(Execution Unit,EU):执行具体操作。
和按序(in-order)流水线相比,乱序处理器需要更大、更复杂的硬件,但是它们能更好地达到更高的指令级并行度。
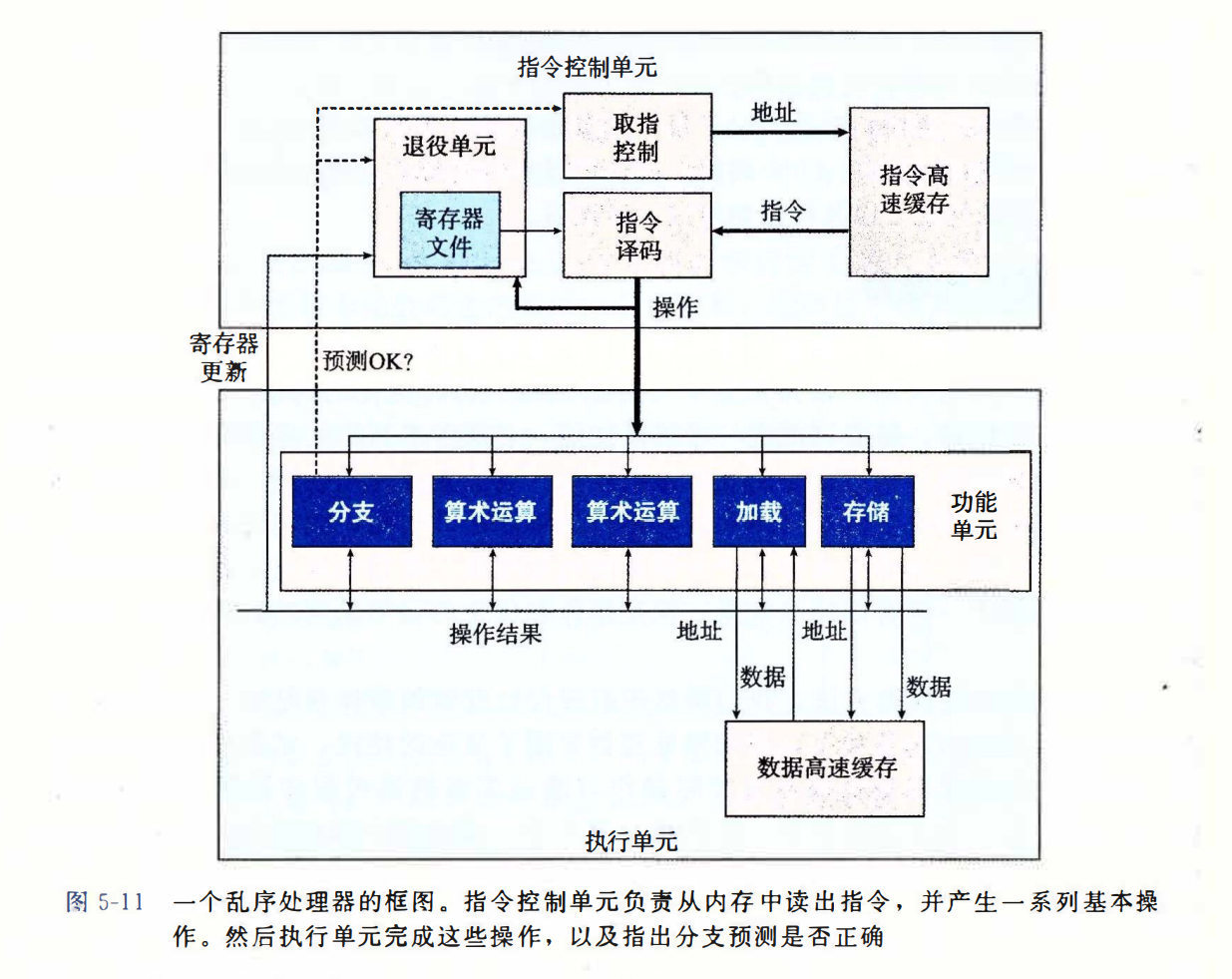
功能单元:
- 0:整数运算、浮点乘、整数和浮点数除法、分支
- 1:整数运算、浮点加、整数乘、浮点乘
- 2:加载、地址计算
- 3:加载、地址计算
- 4:存储
- 5:整数运算
- 6:整数运算、分支
- 7:存储、地址计算
处理器操作的抽象模型
从机器级代码到数据流图。
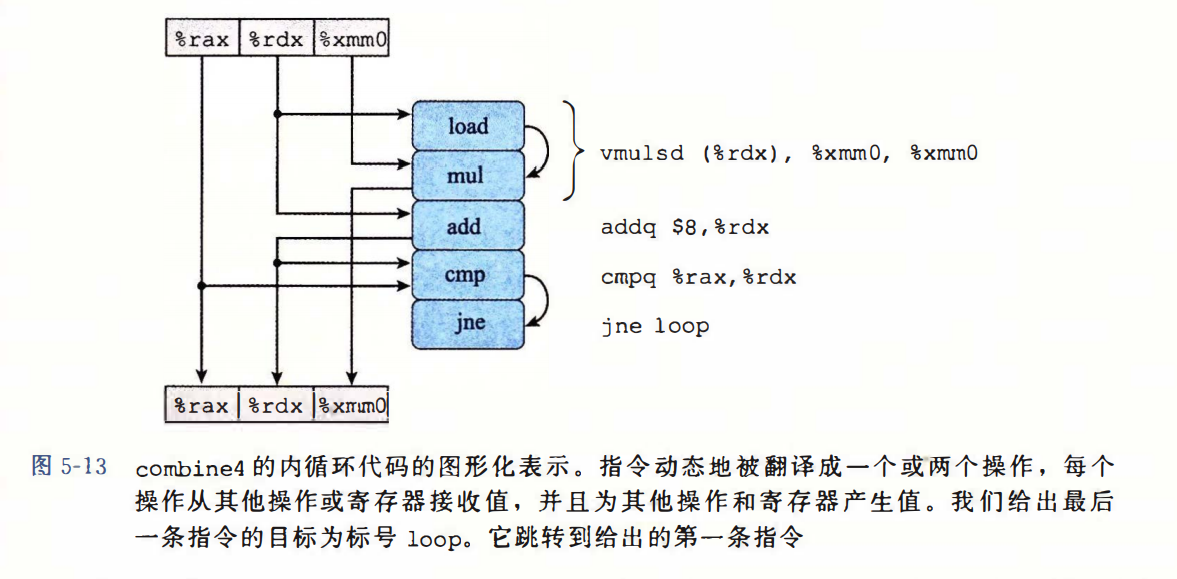
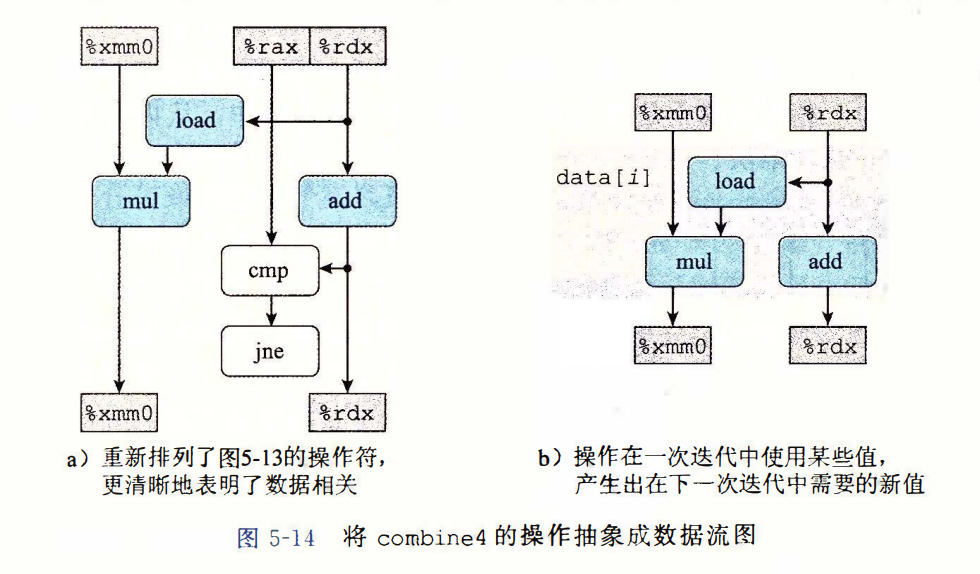
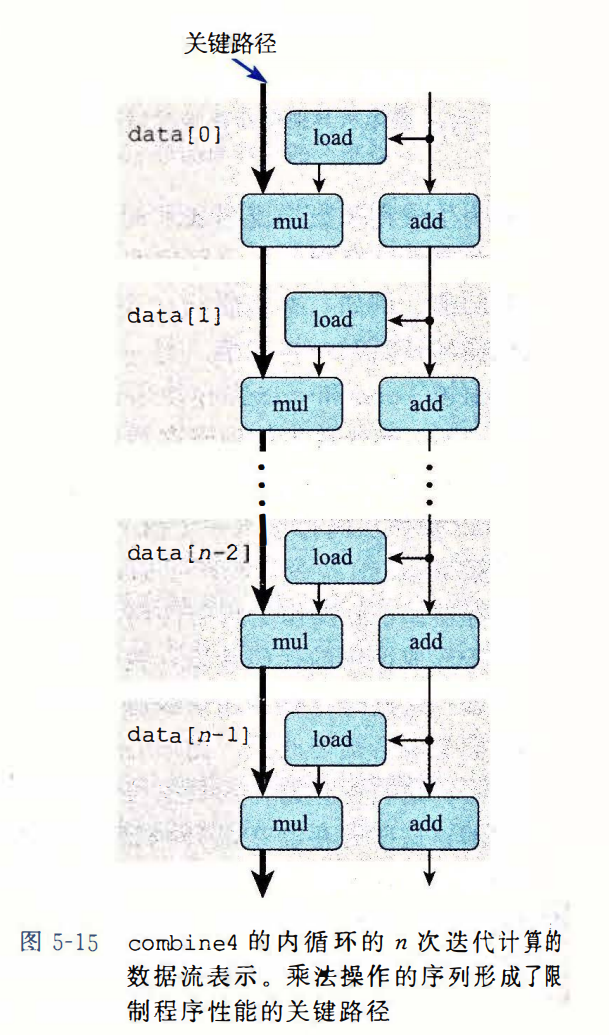
循环展开
- 减少了不直接有助于程序结果的操作的数量,例如循环索引计算和条件分支;
- 提供了一些方法,可以进一步变化代码,减少整个计算中关键路径上的操作数量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 4.循环展开
void combine5(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length - 1;
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for (int i = 0; i < limit; i += 2)
{
acc = (acc OP data[i])OP data[i + 1];
}
for (; i < length; i++)
{
acc = acc OP data[i];
}
*dest = acc;
}
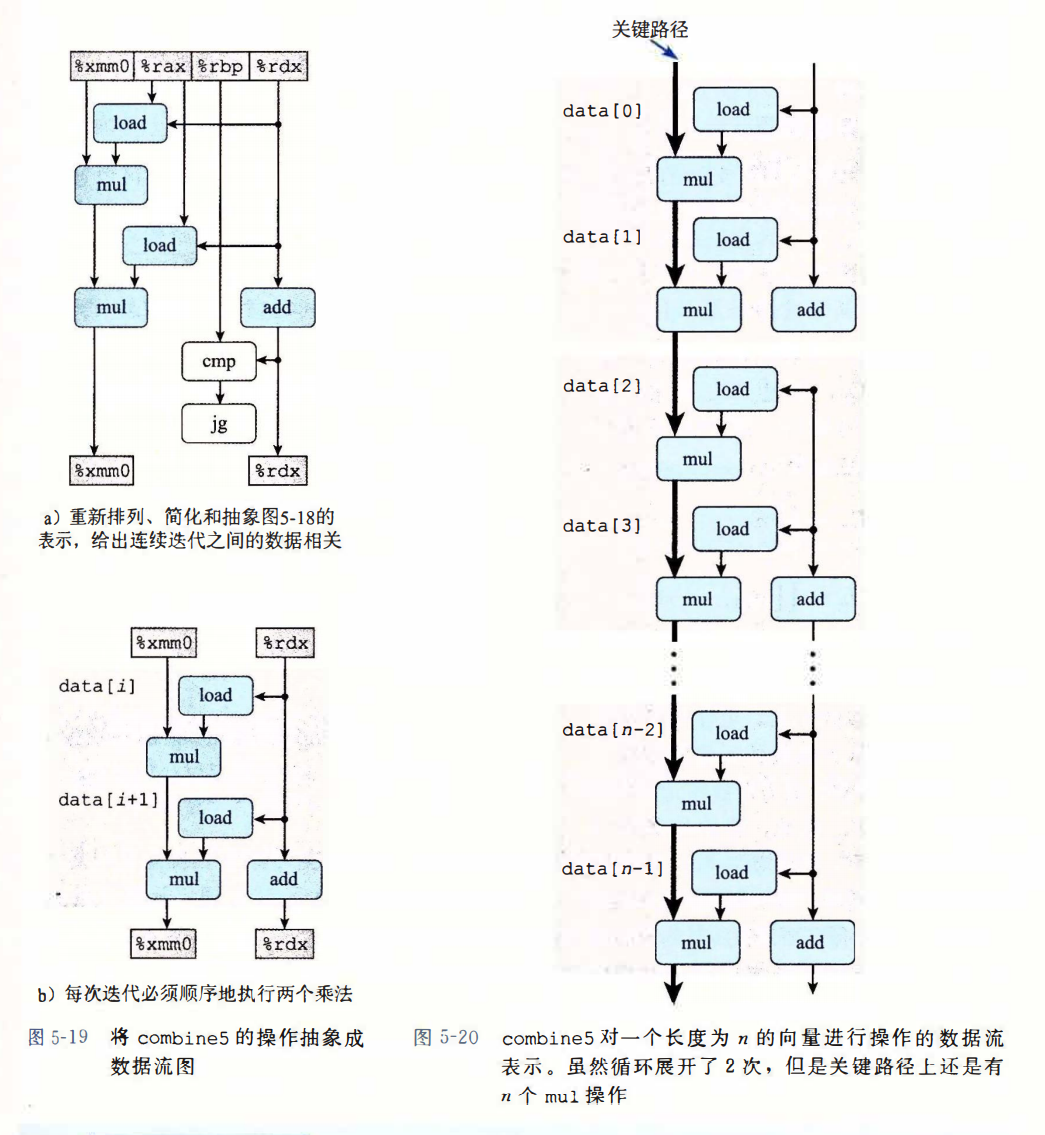
提高并行性
多个累积变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 5.提高并行性
// 5.1 多个累积变量
void combine6(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length - 1;
data_t *data = get_vec_start(v);
data_t acc0 = IDENT;
data_t acc1 = IDENT;
for (int i = 0; i < limit; i += 2)
{
acc0 = acc0 OP data[i];
acc1 = acc1 OP data[i + 1];
}
for (; i < length; i++)
{
acc0 = acc0 OP data[i];
}
*dest = acc0 OP acc1;
}
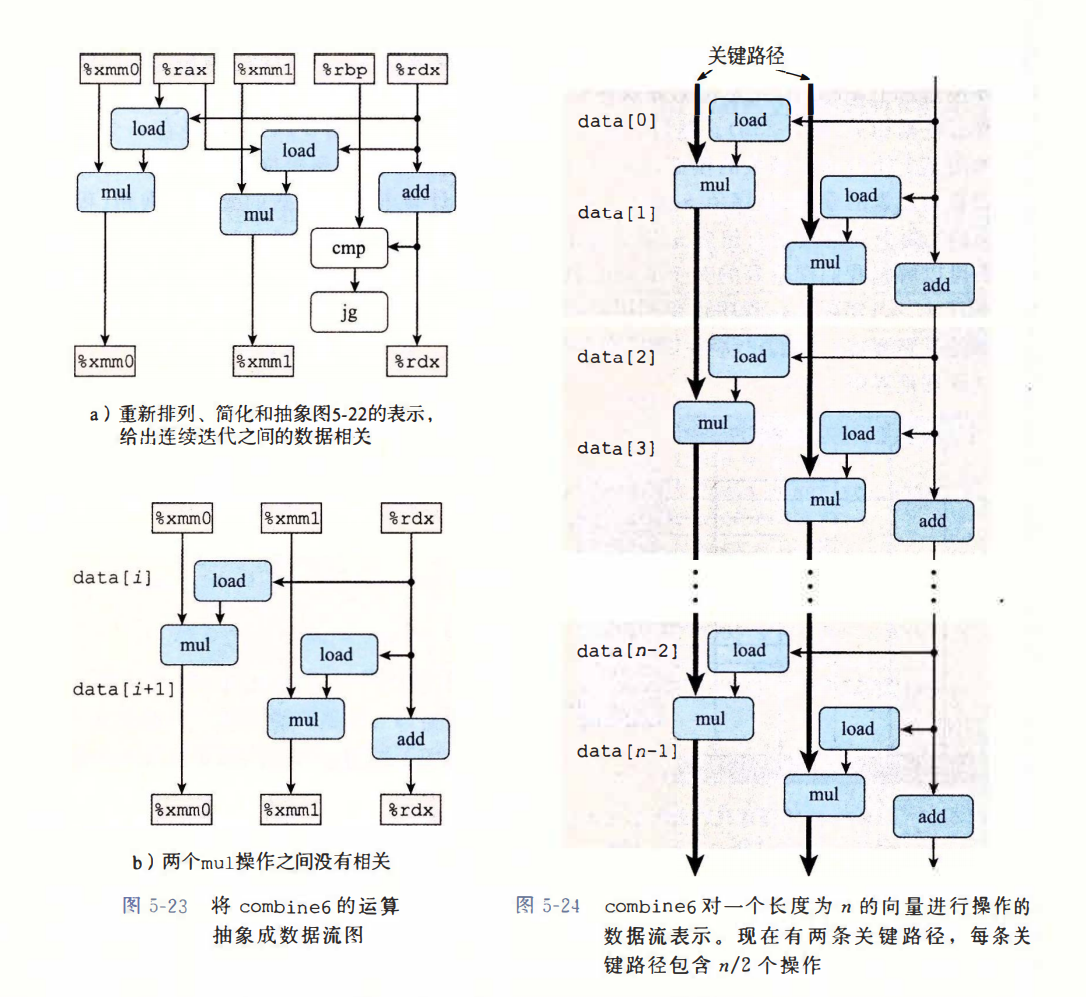
重新结合变换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 5.2 重新结合变换
void combine7(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length - 1;
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for (int i = 0; i < limit; i += 2)
{
// 变换
acc = acc OP (data[i] OP data[i + 1]);
}
for (; i < length; i++)
{
acc = acc OP data[i];
}
*dest = acc;
}
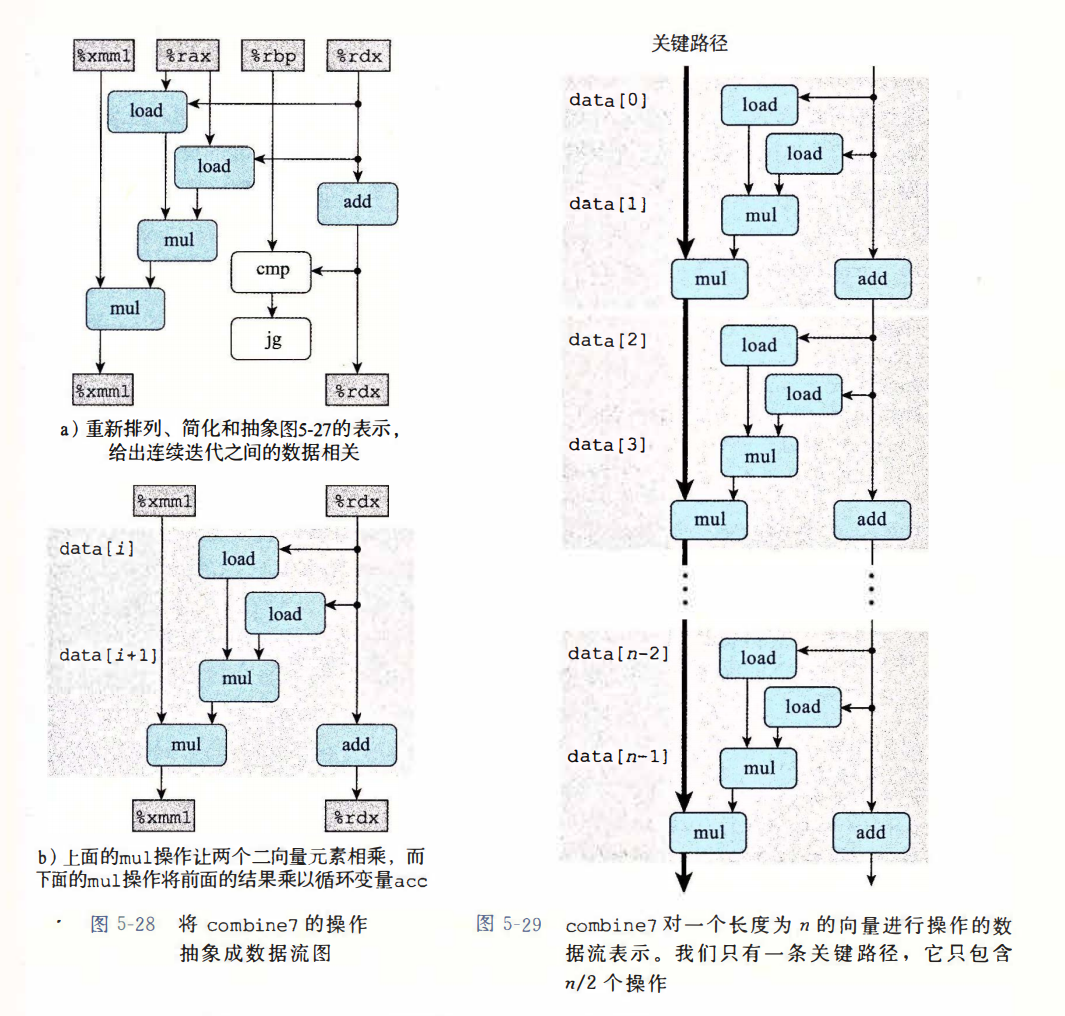
一些限制因素
寄存器溢出
如果并行度p超过了可用的寄存器数量,那么编译器会诉诸溢出(spilling),将某些临时值存放到内存中,通常是在运行时堆栈上分配空间。
一旦编译器必须要诉诸寄存器溢出,那么维护多个累积变量的优势就很可能消失。幸运的是,x86-64有足够多的寄存器,大多数循环在出现寄存器溢出之前就将达到吞吐量限制。
分支预测和预测错误处罚
- 不要过分关心可预测的分支
- 现代处理器中的分支预测逻辑非常善于辨别不同的分支指令的有规律的模式和长期的趋势。
- 书写适合用条件传送实现的代码
理解内存性能
加载的性能
一个包含加载操作的程序的性能既依赖于流水线的能力,也依赖于加载单元的延迟。
一个制约示例CPE的因素是,对于每个被计算的元素,所有的示例都需要从内存读一个值。对两个加载单元而言,其每个时钟周期只能启动一条加载操作,所以CPE不可能小于0.50。对于每个被计算的元素必须加载k个值的应用,不可能获得低于k/2的CPE。
链表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
typedef struct ELE
{
struct ELE *next;
long data;
} list_ele, *list_ptr;
long list_len(list_ptr ls)
{
long len = 0;
while (ls)
{
len++;
// 一条加载操作的结果决定下一条操作的地址
ls = ls->next;
}
return len;
}
存储的性能
与加载对应的是存储(store)操作,它将一个寄存器值写到内存。
写/读相关(write/read dependency)示例:B比A慢。

加载和存储单元:
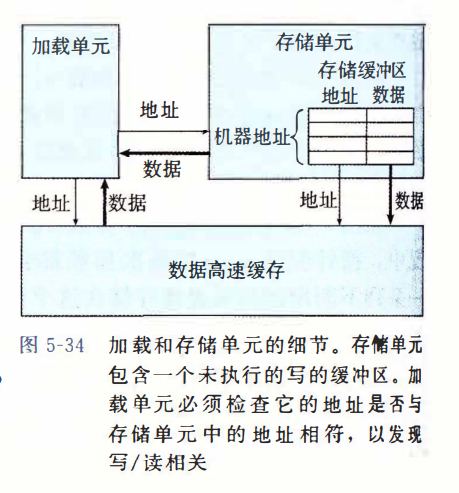
存储单元包含一个存储缓冲区,它包含已经被发射到存储单元而又还没有完成的存储操作的地址和数据,这里的完成包括更新数据高速缓存。提供这样一个缓冲区,使得一系列存储操作不必等待每个操作都更新高速缓冲就能够执行。当一个加载操作发生时,它必须检查存储缓冲区中的条目,看有没有地址相匹配。如果有地址相匹配(意味着在写的字节与读的字节有相同的地址),它就取出相应的数据条目作为加载操作的结果。