Spark 基础
简介
- Spark基于Hadoop1.x架构思想,采用自己的方式改善Hadoop1.x的问题;
- Spark计算基于内存,并且基于Scala开发,(函数式编程)天生适合迭代计算;
- 内存–>优点:快–>缺点:数据丢失–>持久化策略(内存中的数据定期放到磁盘中);
结构:
- Master、ApplicationManager、Driver
- Worker、Executor
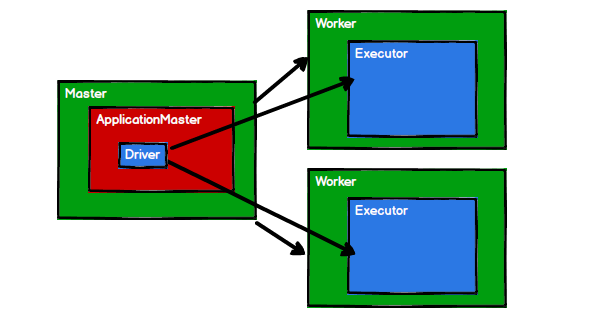
重要角色
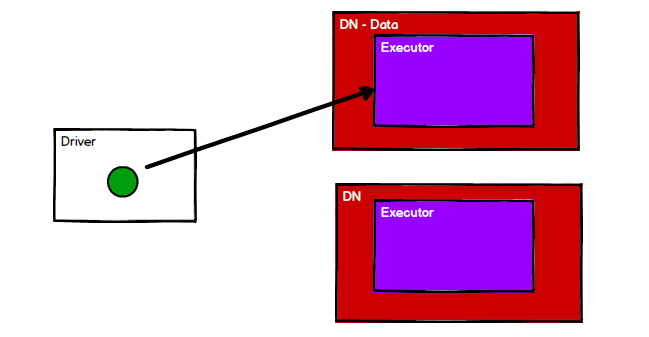
Driver(驱动器)
Spark的驱动器是执行开发程序中的main方法的进程。它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行。如果是用spark shell,那么当启动spark shell的时候,系统后台自启了一个Spark驱动器程序,就是在spark shell中预加载的一个叫作 sc的SparkContext对象。如果驱动器程序终止,那么Spark应用也就结束了。
主要负责:
-
把用户程序转为作业(JOB);
-
跟踪Executor的运行状况;
-
为执行器节点调度任务;
-
UI展示应用运行状况。
Executor(执行器)
Spark Executor是一个工作进程,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
主要负责:
-
负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程;
-
通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
运行模式
Local模式
Local模式就是运行在一台计算机上的模式,通常就是用于本机开发和测试。
- local:所有计算都运行在一个线程中,没有任何并行计算;
- local[K]:指定使用K个线程来运行计算,比如local[4]就是运行4个Worker线程;
- local[*]:按照CPU核数来设置线程数。
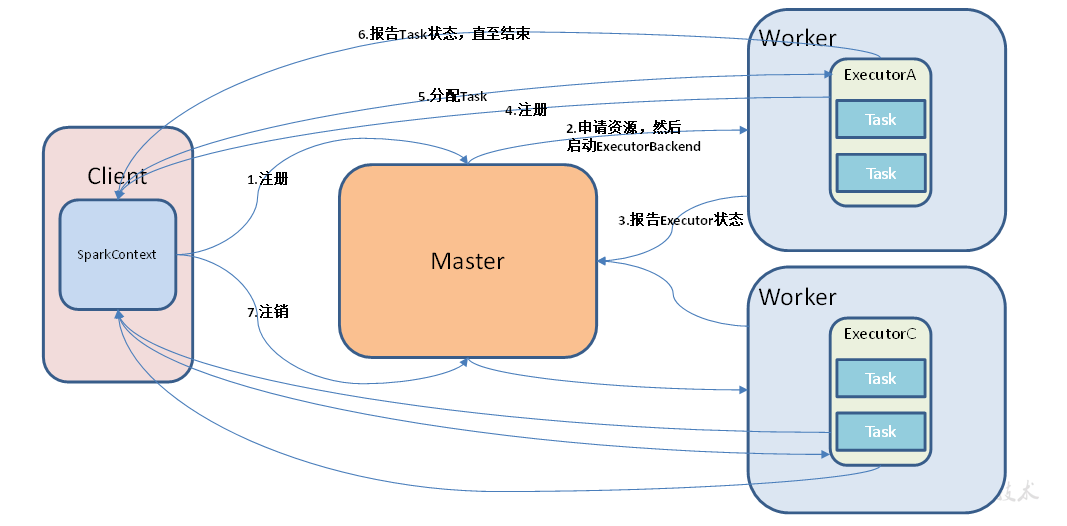
Standalone模式
构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。
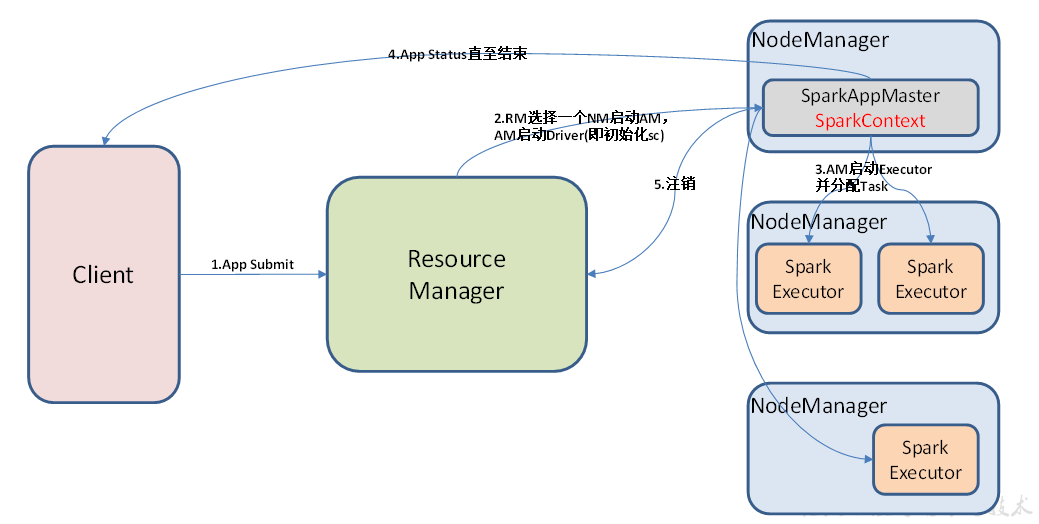
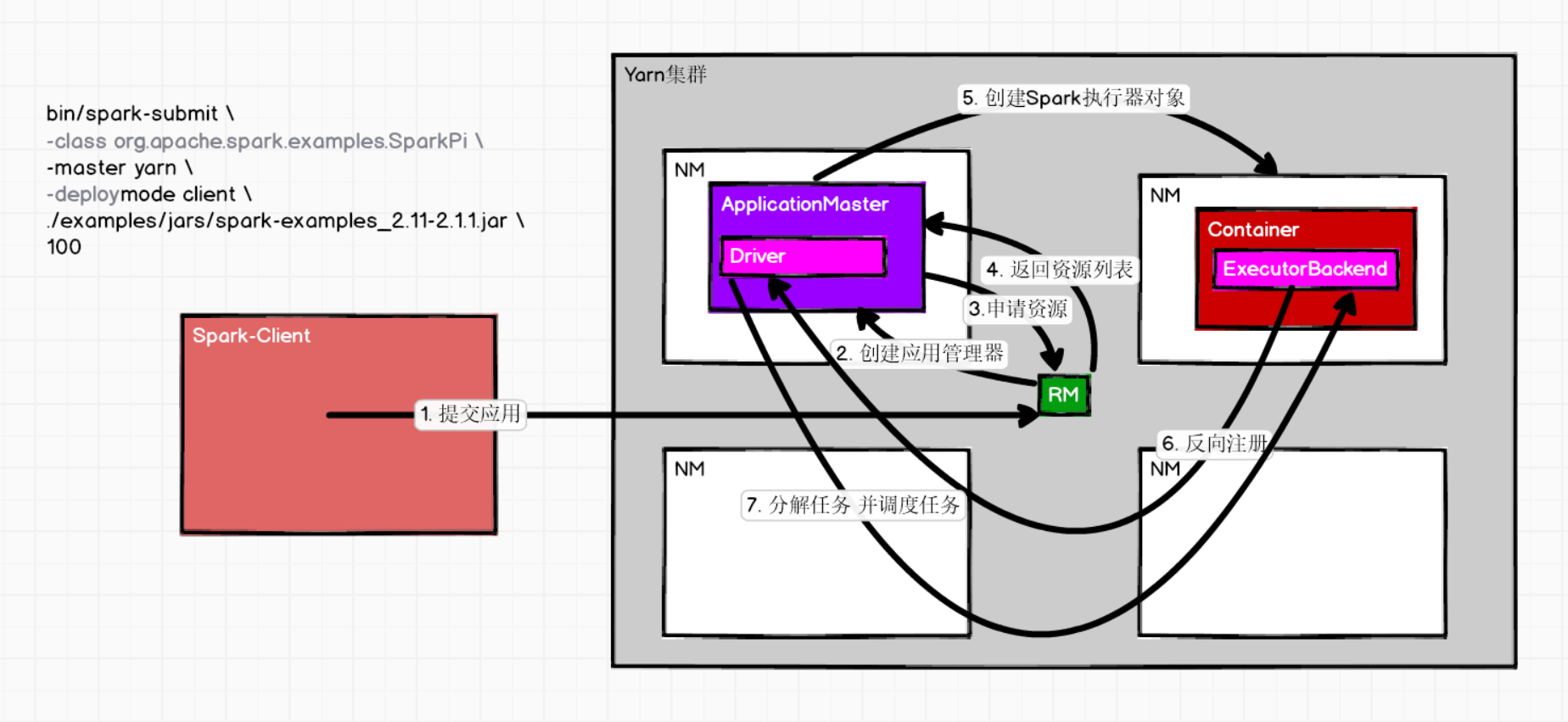
Yarn模式
Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
- yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出;
- yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的APP(APPMaster),适用于生产环境。
其他
- Mesos:Spark客户端直接连接Mesos,不需要额外构建Spark集群;
- Kubernetes:运行在k8s集群上。
Spark数据结构
三大数据结构:RDD、广播变量、累加器。
1. RDD
RDD和JavaIO一样,也体现了装饰者设计模式,将数据处理的逻辑进行封装。
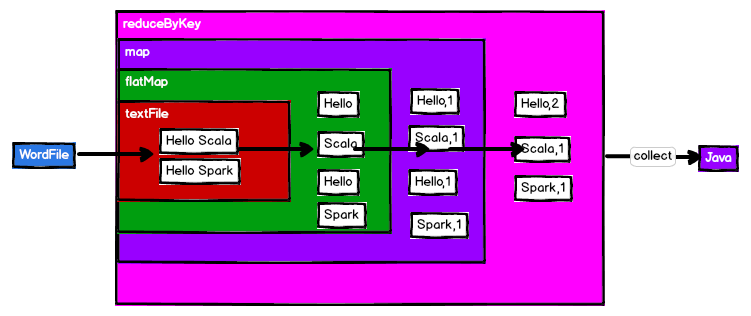
定义
RDD(Resilient Distributed Dataset)弹性分布式数据集:
代码中是一个抽象类,代表一个不可变(只读)、可分区、里面的元素可并行计算的集合。
RDD特性:
(1)数据集:存储的是数据的计算逻辑;
(2)分布式:数据的来源、计算、数据的存储;
(3)弹性:
- 血缘(依赖关系):spark通过特殊的处理方案简化的依赖关系;
- 计算:spark的计算基于内存,性能高,也可以和磁盘灵活切换;
- 分区:spark在创建默认分区后,可以通过指定的算子来改变分区数量;
- 容错:spark在执行计算时,如果发生错误,可以通过依赖重新计算;
(4)数量:
- Executor:可以通过参数设定,默认为2个,一个节点可以多个executor;
- partition:①默认情况下,读取文件采用的是Hadoop的切片规则,如果读取内存中的数据,可以根据特定的算法进行设定;可以通过其他算子进行改变;②多个stage的场合(比如reduceByKey方法),默认下一个阶段的分区数量取决于上一个阶段最后RDD的分区数,但可以在相应的算子中通过参数进行修改;
- Stage:1(ResultStage) + Shuffle依赖的数量(ShuffleMapStage);划分阶段的目的是为了任务执行的等待,因为Shuffle的过程需要落盘;
- Task:原则上一个分区就是一个任务;实际应用中,可以动态调整;
创建
-
从内存中创建:两种函数【parallelize和makeRDD(makeRDD底层也是parallelize)】;
-
从存储中创建;
-
从其他RDD中创建。
属性
-
1) 一组分区(Partition),即数据集的基本组成单位;
-
2) 一个计算每个分区的函数(分区器);
-
3) RDD之间的依赖关系(血缘关系);
-
4) 一个Partitioner,即RDD的分片函数;
-
5) 一个列表,存储存取每个Partition的优先位置(preferred location)。
优先位置:移动数据不如移动计算。
分区:
注意:从文件读取,指定分区数,根据hadoop分片规则计算分片,hadoop按行读取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 例1:
// 文件内容:一行,5个数(5kb)
> 12345
// RDD指定分区数为2
val fileRDD: RDD[String] = sc.textFile("in", 2)
// hadoop计算分片:5 / 2 ==> [2,2,1] 会产生三个分区
// hadoop按行读取,保存RDD
fileRDD.saveAsTextFile("output")
// '12345'整行输出到part-0000,其他两个文件为空
// 例2:
// 文件内容:五行,每行一个数,大小13kb(有换行)
> 1
> 2
> 3
> 4
> 5
// RDD指定分区数为2
val fileRDD: RDD[String] = sc.textFile("in", 2)
// hadoop计算分片:13 / 2 ==> [6,6,1] 会产生三个分区
// hadoop按行读取,保存RDD
fileRDD.saveAsTextFile("output")
// '1[换行]2[换行]3[换行]'输出到part-0000,'4[换行]5'输出到part-0001,part-0002为空
使用(算子):
所有RDD的方法都称为算子,分为转换和行动两种功能的算子。
1)转换算子
(1)单Value类型:
- map(func):RDD每个元素经过func函数转换;
1
2
3
var source = sc.parallelize(1 to 10)
// 每个元素乘以二
val mapadd = source.map(_ * 2)
- mapPartitions(func):独立在RDD每个分区上运行;
1
2
val rdd = sc.parallelize(Array(1,2,3,4))
rdd.mapPartitions(x=>x.map(_*2))
- mapPartitionWithIndex(func):拿到分区号;
1 2
val rdd = sc.parallelize(Array(1,2,3,4)) val indexRdd = rdd.mapPartitionsWithIndex((index,items)=>(items.map((index,_))))
- flatMap(func):每一个输入元素被映射为0或多个输出元素(所以func应该返回一个序列);
1 2 3 4
val sourceFlat = sc.parallelize(1 to 5) val flatMap = sourceFlat.flatMap(1 to _) flatMap.collect() // res0: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5)
- glom():将每一个分区形成一个数组(用法例子:求每个分区最大数);
1 2 3
val rdd = sc.parallelize(1 to 16,4) rdd.glom().collect() // res1: Array[Array[Int]] = Array(Array(1, 2, 3, 4), Array(5, 6, 7, 8), Array(9, 10, 11, 12), Array(13, 14, 15, 16))
- groupBy(func):分组,按照传入函数的返回值进行分组;
1 2
val rdd = sc.parallelize(1 to 4) val group = rdd.groupBy(_%2)
- filter(func):过滤,保留经过func函数计算后返回值为true的元素;
1 2
var sourceFilter = sc.parallelize(Array("xiaoming","xiaojiang","xiaohe","dazhi")) val filter = sourceFilter.filter(_.contains("xiao"))
- sample(withReplacement,fraction, seed):抽样,(是否放回、抽取比例、随机种子);
1 2 3 4 5
val rdd = sc.parallelize(1 to 10) // 放回抽样 var sample1 = rdd.sample(true,0.4,2) // 不放回抽样 var sample2 = rdd.sample(false,0.2,3)
- distinct([numPartitions]):去重,numPartitions指定并行度(分区数),默认为8,数据会打乱重组【shuffle】;
1 2 3 4
val distinctRdd = sc.parallelize(List(1,2,1,5,2,9,6,1)) val unionRDD = distinctRdd.distinct() // 指定并行度 val unionRDD = distinctRdd.distinct(2)
- coalesce(numPartitions,[shuffle]):缩减分区数,用于大数据集过滤后,提高小数据集的执行效率;默认简单的合并分区没有shuffle;
1 2
val rdd = sc.parallelize(1 to 16,4) val coalesceRDD = rdd.coalesce(3)
- repartion(numPartitions):根据分区数,重新打乱重组,shuffle;
1 2
val rdd = sc.parallelize(1 to 16,4) val rerdd = rdd.repartition(2)
- sortBy(func,[ascending],[numTasks]):排序。
1 2 3 4 5
val rdd = sc.parallelize(List(2,1,3,4)) rdd.sortBy(x => x).collect() // 按照自身大小排序 // res11: Array[Int] = Array(1, 2, 3, 4) rdd.sortBy(x => x%3).collect() // 按照与3余数的大小排序 // res12: Array[Int] = Array(3, 4, 1, 2)
- pipe():管道,针对每个分区,都执行一个shell脚本,返回输出的RDD。
对比:
① map 和 mapPartitions:map是一个一个元素迭代计算,每个元素对应一个executor,效率较低;mapPartitions把整个分区一次性发送到executor,效率更高,但可能会OOM。
② coalesce 和 repartion:coalesce重新分区,可以选择是否进行shuffle,由参数决定;repartion实际上是调用coalesce,默认进行shuffle。
注意:一个分区划分一个任务(Task)
(2)双Value类型:
- union(otherDataset):并集;
- subtract(otherDataset):差集;
- intersection(otherDataset):交集;
- cartesian(otherDataset):笛卡尔积;
- zip(otherDataset):将两个RDD组合成K-V形式的RDD,默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常;
1 2 3 4 5 6 7 8 9 10 11 12
val rdd1 = sc.parallelize(1 to 6) val rdd2 = sc.parallelize(5 to 10) // union rdd1.union(rdd2).collect() // subtract rdd1.subtract(rdd2).collect() // intersection rdd1.intersection(rdd2).collect() // cartesian rdd1.cartesian(rdd2).collect() // zip rdd1.zip(rdd2).collect()
(3)K-V类型:
- partitionBy(分区器):对pairRDD进行分区,如果原有partionRDD和目标partitionRDD是一致的话就不进行分区,否则会生成ShuffleRDD,即会产生Shuffle过程;
1 2
val rdd = sc.parallelize(Array((1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd")),4) var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
- groupByKey:根据key分组,生成sequence;
1 2 3 4
val words = Array("one", "two", "two", "three", "three", "three") val group = wordPairsRDD.groupByKey() // 计算相同key对应值的相加结果 group.map(t => (t._1, t._2.sum))
- reduceByKey(func,[numTasks]):将相同的key值聚合到一起根据func计算得到结果,reduce任务的个数可以通过numTasks设置;
1 2
val rdd = sc.parallelize(List(("female",1),("male",5),("female",5),("male",2))) val reduce = rdd.reduceByKey((x,y) => x+y)
-
aggregateByKey(zeroValue:U,[partitioner: Partitioner])(seqOp:(U,V)=>U,combOp:(U,U)=>U):根据key进行聚合,用在分区内和分区间聚合规则不一样的时候;
- zeroValue:零值(初始值);
- seqOp:sequenceOperation,一个分区内运算规则;
- combOp:combineOperation,分区间运算规则;
1
2
3
4
5
6
7
8
val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),2)
// 用例:求pairRDD每个分区相同key对应的最大值,然后相加;
val agg = rdd.aggregateByKey(0)(math.max(_,_),_+_)
agg.collect()
// res0: Array[(String, Int)] = Array((b,3), (a,3), (c,12))
// WordCount
rdd.aggregateByKye(0)(_+_,_+_)
- foldByKey:aggregateByKey的简化操作,sepOp和combOp相同;
1 2 3 4
val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3) val agg = rdd.foldByKey(0)(_+_) agg.collect() // res61: Array[(Int, Int)] = Array((3,14), (1,9), (2,3))
- combineByKey(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C):对相同K,把V合并成一个集合;例如求均值;
1
2
3
val input = sc.parallelize(Array(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),2)
val combine = input.combineByKey((_,1),(acc:(Int,Int),v)=>(acc._1+v,acc._2+1),(acc1:(Int,Int),acc2:(Int,Int))=>(acc1._1+acc2._1,acc1._2+acc2._2))
val result = combine.map{case (key,value) => (key,value._1/value._2.toDouble)}
- sortByKey:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD;
1 2 3 4 5
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd"))) rdd.sortByKey(true).collect() // res9: Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc)) rdd.sortByKey(false).collect() // res10: Array[(Int, String)] = Array((6,cc), (3,aa), (2,bb), (1,dd))
- mapValues:针对于(K,V)形式的类型只对V进行操作;
1 2 3
val rdd3 = sc.parallelize(Array((1,"a"),(1,"d"),(2,"b"),(3,"c"))) rdd3.mapValues(_+"|||").collect() // res12: Array[(Int, String)] = Array((1,a|||), (1,d|||), (2,b|||), (3,c|||))
- join:类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD;
1 2 3 4
val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c"))) val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6))) rdd.join(rdd1).collect() // res13: Array[(Int, (String, Int))] = Array((1,(a,4)), (2,(b,5)), (3,(c,6)))
- cogroup:在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable
,Iterable ))类型的RDD; 1 2 3 4
val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c"))) val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6))) rdd.cogroup(rdd1).collect() // res14: Array[(Int, (Iterable[String], Iterable[Int]))] = Array((1,(CompactBuffer(a),CompactBuffer(4))), (2,(CompactBuffer(b),CompactBuffer(5))), (3,(CompactBuffer(c),CompactBuffer(6))))
对比:
① groupByKey 和 reduceByKey:groupByKey按照key进行分组,直接进行shuffle;reduceByKey按照key进行聚合,在shuffle之前有combine操作,shuffle有combine操作可以提高性能,返回结果是RDD[k,v];
2)行动算子
- reduce(func):通过func函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据;
1
2
3
4
5
6
val rdd1 = sc.makeRDD(1 to 10,2)
rdd1.reduce(_+_)
val rdd2 = sc.makeRDD(Array(("a",1),("a",3),("c",3),("d",5)))
rdd2.reduce((x,y)=>(x._1 + y._1, x._2 + y._2))
// res23: (String, Int) = (adca,12)
- collect:在驱动程序中,以数组的形式返回数据集的所有元素;
- count:返回RDD中元素的个数;
- first:返回RDD中的第一个元素;
- take(n):返回一个由RDD的前n个元素组成的数组;
- takeOrdered(n):返回该RDD排序后的前n个元素组成的数组;
- aggregate(zeroValue: U)(seqOp: (U,T) ⇒ U, combOp: (U, U) ⇒ U):将每个分区里面的元素通过seqOp和初始值进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作;最终返回的类型不需要和RDD中元素类型一致;
- fold:折叠操作,aggregate的简化操作,seqop和combop一样;
- saveAs**:保存到文件;
- countByKey:针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数;
- foreach(func):在数据集的每一个元素上,运行函数func进行更新。
RDD中的函数传递
对于RDD的操作,初始化工作是在Driver端进行的,而实际运行程序是在Executor端进行的,这就涉及到了跨进程通信,是需要序列化的。需要继承Serializable。
主要是分清哪些代码在Driver端执行,哪些代码在Executor端执行。
RDD依赖关系
1)Lineage(血缘)
RDD只支持粗粒度转换,即在大量记录上执行的单个操作,将创建RDD的一系列Lineage(血缘)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
2)窄依赖、宽依赖
- 窄依赖:指的是每一个父RDD的Partition最多被子RDD的一个Partition使用;(独生子女)
- 宽依赖:指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle。(超生)
3)DAG
原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
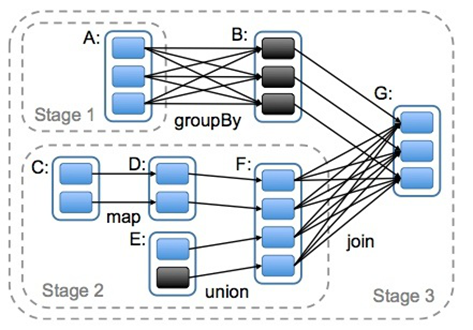
4)任务划分
RDD任务切分中间分为:Application、Job、Stage和Task:
(1)Application:初始化一个SparkContext即生成一个Application;
(2)Job:一个Action算子就会生成一个Job;
(3)Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage;
(4)Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task。
注意:Application->Job->Stage-> Task每一层都是1对n的关系。
5)RDD缓存
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中。
但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。
缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
6)RDD CheckPoint
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
RDD(K-V型)数据分区器
Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle过程属于哪个分区和Reduce的个数
- (1)只有Key-Value类型的RDD才有分区器的,非Key-Value类型的RDD分区器的值是None
- (2)每个RDD的分区ID范围:0 ~ numPartitions-1。
HashPartitioner
HashPartitioner分区的原理:对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则用余数+分区的个数(否则加0),最后返回的值就是这个key所属的分区ID。
HashPartitioner分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据。
RangePartitioner
RangePartitioner作用:将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。实现过程为:
第一步:先重整个RDD中抽取出样本数据,将样本数据排序,计算出每个分区的最大key值,形成一个Array[KEY]类型的数组变量rangeBounds;
第二步:判断key在rangeBounds中所处的范围,给出该key值在下一个RDD中的分区id下标;该分区器要求RDD中的KEY类型必须是可以排序的
自定义分区
继承 org.apache.spark.Partitioner 类并实现下面三个方法。
(1)numPartitions: Int:返回创建出来的分区数。
(2)getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。
(3)equals():Java 判断相等性的标准方法。Spark 需要用这个方法来检查分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个 RDD 的分区方式是否相同。
2. 广播变量
分布式共享只读数据。为了提高效率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
object SparkShareData{
def main(args: Array[String]): Unit = {
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkShareData")
val sc = new SparkContext(config)
val rdd1 = sc.makeRDD(List((1, "a"), (2, "b"), (3, "c")))
val rdd2 = sc.makeRdd(List((1, 1), (2, 2), (3, 3)))
// join,shuffle
val joinRDD: RDD[(Int, (String, Int))] = rdd1.join(rdd2)
joinRDD.foreach(println)
// 可以使用广播变量减少数据的传输
val list = sc.makeRdd(List((1, 1), (2, 2), (3, 3)))
// 构建广播变量
val broadcast: Broadcast[List[(Int, Int)]] = sc.broadcast(list)
val resultRDD: RDD[(Int, (String, Int))] = rdd1.map{ // map,无shuffle
case(key, value) => {
val v2: Any = null
// 使用广播变量
for(t <- broadcast.value){
if(key == t._1){
v2 = t._2
}
}
(key, (value, v2))
}
}
resultRDD.forreach(println)
sc.stop()
}
}
3. 累加器
分布式共享只读数据。累加器不只是加法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
object SparkShareData{
def main(args: Array[String]): Unit = {
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkShareData")
val sc = new SparkContext(config)
val dataRDD: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
// 求和
val sum: Int = dataRDD.reduce(_+_)
println(sum) // 10
var sum = 0
dataRDD.foreach(i => sum=sum+i)
println(sum) // 0,sum在Driver中,而sum=sum+i在Executor中执行
// 累加器共享变量(只写)
val accumulator:LongAccmulator = sc.longAccumulator
dataRDD.foreach{
case i => {
accumulator.add(i)
}
}
print(accumulator.value) // 10
sc.stop()
}
}
自定义类加器:
- 继承AccumulatorV2;
- 实现抽象方法:isZero()、copy()、reset()、add()、merge()、value();
- 创建累加器:new myAccumulator
- 注册累加器:sc.register(myAccumulator)
- 执行累加:myAccumulator.add()
- 获取累加器值:myAccumulator.value
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
object SparkShareData{
def main(args: Array[String]): Unit = {
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkShareData")
val sc = new SparkContext(config)
val dataRDD: RDD[String] = sc.makeRDD(List("hadoop","hive","hbase","Scala","Spark"),2)
val wordAccumulator = new WordAccumulator
sc.register(wordAccumulator)
dataRDD.foreach{
case word => {
wordAccumulator.add(word)
}
}
println(wordAccumulator.value) // [hadoop, hive, hbase]
sc.stop()
}
}
class WordAccumulator extends AccumulatorV2[String, util.ArrayList[String]] {
val list = new util.ArrayList[String]()
// 当前累加器是否为初始状态
override def isZero: Boolean = list.isEmpty
// 复制累加器对象
override def copy(): AccumulatorV2[String, util.ArrayList[String]] = {
new WordAccumulator()
}
// 重置累加器对象
override def reset(): Unit = {
list.clear()
}
// 向累加器中增加数据
override def add(v: String): Unit = {
if(v.contains("h")){
list.add(v)
}
}
// 合并累加器
override def merge(other: AccumulatorV2[String, util.ArrayList[String]]): Unit = {
list.add(other.value)
}
// 获取累加器的值
override def value: util.ArrayList[String] = list
}
SparkSQL
RDD、DataFrame、DataSet
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet。
- DataFrame:二维表,底层优化执行;
- DataSet:是Dataframe API的一个扩展,是Spark最新的数据抽象;
在后期的Spark版本中,DataSet会逐步取代RDD和DataFrame成为唯一的API接口。
三者间可以相互转换。
注意:如果需要RDD与DF或者DS之间操作,那么都需要引入 import spark.implicits._ 【spark不是包名,而是sparkSession对象的名称】
RDD
优点:
- 编译时类型安全:编译时就能检查出类型错误
- 面向对象的编程风格:直接通过类名点的方式来操作数据
缺点:
- 序列化和反序列化的性能开销:无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化.
- GC的性能开销:频繁的创建和销毁对象, 势必会增加GC
DataFrame
优点:
- DataFrame引入了schema和off-heap:
- schema : RDD每一行的数据, 结构都是一样的. 这个结构就存储在schema中. Spark通过schame就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了.
- off-heap : 意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时, 就直接操作off-heap内存. 由于Spark理解schema, 所以知道该如何操作. 缺点:
- DataFrame解决了RDD的缺点, 但是却丢了RDD的优点. DataFrame不是类型安全的, API也不是面向对象风格的.
DataSet
DataSet结合了RDD和DataFrame的优点, 并带来的一个新的概念Encoder。
当序列化数据时, Encoder产生字节码与off-heap进行交互, 能够达到按需访问数据的效果, 而不用反序列化整个对象。
用户自定义UDF函数:
1
2
3
4
val df = spark.read.json("examples/src/main/resources/people.json")
spark.udf.register("addName", (x:String)=> "Name:"+x)
df.createOrReplaceTempView("people")
spark.sql("Select addName(name), age from people").show()
用户自定义聚合函数:
- 弱类型:继承UserDefinedAggregateFunction
- 强类型:继承Aggregator。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Encoders
import org.apache.spark.sql.SparkSession
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverage extends Aggregator[Employee, Average, Double] {
// 定义一个数据结构,保存工资总数和工资总个数,初始都为0
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// 聚合不同execute的结果
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// 计算输出
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// 设定之间值类型的编码器,要转换成case类
// Encoders.product是进行scala元组和case类转换的编码器
def bufferEncoder: Encoder[Average] = Encoders.product
// 设定最终输出值的编码器
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
// main
val spark = SparkSession
.builder()
.appName("SparkSQL")
.config(sparkConf)
.getOrCreate()
import spark.implicits._
val ds = spark.read.json("***.json").as[Employee]
// Convert the function to a `TypedColumn` and give it a name
val averageSalary = MyAverage.toColumn.name("average_salary")
val result = ds.select(averageSalary)
SparkSQL数据源
SparkSQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项spark.sql.sources.default,可修改默认数据源格式。
当数据源格式不是parquet格式文件时,需要手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),如果数据源格式为内置格式,则只需要指定简称定json, parquet, jdbc, orc, libsvm, csv, text来指定数据的格式。
SparkSession提供的read.load方法用于通用加载数据,使用write和save保存数据。
Spark使用Hive
Spark内置一个Hive,如果使用内部的Hive,在Spark2.0之后,spark.sql.warehouse.dir用于指定数据仓库的地址,如果需要是用HDFS作为路径,那么需要将core-site.xml和hdfs-site.xml 加入到Sparkconf目录,否则只会创建master节点上的warehouse目录,查询时会出现文件找不到的问题。
要使用外部Hive,将Hive中的hive-site.xml拷贝或者软连接到Spark安装目录下的conf目录下。